
Você já deve ter lido diversos artigos explicando o que é modelagem de dados. Mas quando chega a hora de realmente criar um modelo para seu projeto, as dúvidas aparecem: por onde começar? Como traduzir as necessidades do negócio em um diagrama funcional? Como fazer um banco de dados no SQL?
E este artigo foi criado para ser seu guia prático, levando você desde a primeira conversa com o cliente até a implementação final do banco de dados.

O que é modelagem de dados?
Modelagem de dados é o processo de criar uma representação visual e estruturada de como as informações serão organizadas, armazenadas e relacionadas dentro de um sistema de banco de dados. Ou seja, trata-se de desenhar um mapa completo que mostra quais dados sua empresa precisa coletar, como esses dados se conectam entre si e de que forma eles serão acessados e utilizados no dia a dia.
Tipos de modelagem de dados
Antes de mergulharmos nas etapas práticas da modelagem, é importante entender que existem diferentes tipos de modelagem, cada um adequado para finalidades específicas.
Modelagem relacional
A modelagem relacional é o tipo mais comum e adequado para sistemas transacionais, aqueles usados no dia a dia das operações de uma empresa. Pense em um sistema de e-commerce onde clientes fazem pedidos, produtos são atualizados, pagamentos são processados. Todas essas são transações que precisam ser registradas e atualizadas constantemente.
Na modelagem relacional, as informações são organizadas em tabelas que se relacionam entre si através de chaves. A grande vantagem desse modelo é que ele minimiza redundância através de um processo chamado normalização. Cada informação tem seu lugar específico no banco de dados, e quando você precisa dela, busca através dos relacionamentos estabelecidos.
Por exemplo, em um sistema de gestão de clientes, você tem uma tabela de clientes com todas as informações pessoais, uma tabela de pedidos com os detalhes de cada compra, e uma tabela de produtos com as informações dos itens vendidos. Quando você quer saber quais produtos um cliente específico comprou, o banco de dados segue os relacionamentos entre essas tabelas para trazer a informação completa.
A maioria dos sistemas de gerenciamento de banco de dados relacionais, como PostgreSQL, MySQL e SQL Server, são otimizados para esse tipo de modelagem.
-4.jpg?width=1024&height=512&name=unnamed%20(1)-4.jpg)
Modelagem dimensional
Já a modelagem dimensional funciona de forma diferente e é especialmente para sistemas de análise de dados, business intelligence e data warehouses. Enquanto a modelagem relacional prioriza evitar redundância, a modelagem dimensional prioriza facilitar consultas analíticas rápidas, mesmo que isso signifique repetir algumas informações.
Na modelagem dimensional, você organiza os dados ao redor de uma tabela fato central que contém as métricas numéricas que você quer analisar, como valores de vendas, quantidades, custos. Ao redor dessa tabela fato ficam as tabelas dimensão, que contêm os atributos descritivos que você usa para filtrar e agrupar suas análises, como informações de produtos, clientes, tempo e localização.
Voltando ao exemplo do e-commerce, uma tabela fato de vendas poderia conter o valor de cada venda, a quantidade vendida e o desconto aplicado. As dimensões descreveriam o contexto dessa venda: qual produto foi vendido (dimensão produto com nome, categoria, marca), quem comprou (dimensão cliente com dados demográficos), quando foi vendido (dimensão tempo com data, mês, trimestre, ano) e onde foi entregue (dimensão localização com cidade, estado, região).
Na prática, muitas empresas mantêm dois bancos de dados separados: um relacional para as operações do dia a dia e um dimensional para análises estratégicas.
As etapas da modelagem de dados na prática
Agora que você compreende os conceitos fundamentais, vamos ao processo prático de criar um modelo de dados do zero.
A modelagem segue uma sequência lógica de etapas que constroem umas sobre as outras, cada fase refinando e adicionando detalhes ao trabalho da fase anterior.
1. Entendimento do problema e coleta de requisitos
Antes de criar tabelas, diagramas ou escolher tecnologias, você precisa entender:
-
O que o negócio precisa?
-
Quais perguntas precisam ser respondidas?
-
Quais processos precisam ser apoiados?
Como fazer isso na prática
-
Reuniões de levantamento de requisitos.
-
Entrevistas com usuários.
-
Análise de processos já existentes.
-
Mapear fluxos reais de informação.
Exemplo
Imagine que o negócio quer acompanhar vendas. As perguntas poderiam ser:
-
“Quanto vendemos por mês?”
-
“Qual produto vende mais?”
-
“Quem são os melhores clientes?”
2. Identificação das entidades
Entidades são coisas importantes sobre as quais você quer guardar dados.
Normalmente são substantivos:
-
Cliente.
-
Produto.
-
Pedido.
-
Pagamento.
Como identificar entidades facilmente
Pegue uma frase do negócio:
“O cliente compra produtos através de pedidos.”
As entidades são:
- Cliente;
- Produto;
- Pedido.

3. Definição dos atributos
Atributos são as informações que você guarda sobre cada entidade.
Exemplo
Entidade Cliente → atributos possíveis:
-
id_cliente;
-
nome;
-
email;
-
data_nascimento;
-
cidade.
Entidade Produto:
-
id_produto;
-
nome;
-
categoria;
-
preço.
Dicas práticas
-
Evite atributos duplicados.
-
Cada atributo deve ter apenas um significado.
-
Sempre inclua um identificador único (chave primária).
4. Definição dos relacionamentos
Relacionamento indica como as entidades se conectam.
Os tipos possíveis:
-
1 para 1 (1:1).
-
1 para muitos (1:N).
-
Muitos para muitos (N:N).
Exemplos claros
-
1 cliente pode fazer muitos pedidos → Cliente 1:N Pedido.
-
1 pedido pode ter muitos produtos → Pedido N:N Produto.
-
Para resolver N:N, você cria uma tabela intermediária como Itens_do_Pedido.
-
Como saber o relacionamento?
Pergunte: “Um X pode ter quantos Y?”
5. Normalização ou desnormalização
Normalização
É organizar as tabelas para:
-
reduzir duplicidades.
-
melhorar consistência.
-
evitar problemas de atualização.
Usada principalmente em sistemas transacionais (OLTP).
Desnormalização
É simplificar tabelas para:
-
melhorar performance de leitura.
-
facilitar análises.
Usada em Data Warehouses, OLAP, BI.
Regra simples para iniciantes:
-
Se for sistema operacional → normalize.
-
Se for para análise (BI/Analytics) → desnormalize em um modelo dimensional.
6. Criação do modelo conceitual (Diagrama ER)
É o modelo mais simples e visual, onde você mostra:
-
Entidades.
-
Relacionamentos.
Exemplo de como ficaria:

7. Criação do modelo lógico
Aqui você já inclui detalhes técnicos, como:
-
atributos.
-
chaves primárias.
-
chaves estrangeiras.
-
cardinalidades exatas.
Exemplo:
Tabela cliente
-
id_cliente (PK).
-
nome.
-
email.
Tabela pedido
-
id_pedido (PK).
-
id_cliente (FK).
-
data_pedido.
Mesmo neste nível, ainda não falamos de SQL nem do banco.
8. Criação do modelo físico
Agora sim definimos:
-
tipo de dados (varchar, int, date…).
-
índices.
-
constraints.
-
nome exato das tabelas.
Exemplo real:

9. Validação com o negócio e ajustes
Essa fase é fundamental.
Você apresenta o modelo e confirma:
-
As entidades fazem sentido?
-
Os atributos atendem às necessidades?
-
Os relacionamentos estão corretos?
-
Alguma informação está faltando?
É normal ajustar várias vezes. Modelagem é um processo iterativo.
Modelagem de dados: do zero até banco de dados
Agora vamos transformar tudo em prática real, como se você estivesse entrando no seu primeiro projeto de dados em uma empresa.
O cenário será simples, mas suficiente para entender 90% dos casos reais de modelagem de dados.
No nosso caso usaremos:
-
Clientes;
-
Produtos;
-
Pedidos;
-
Itens_do_pedido (resolve o relacionamento N:N entre pedidos e produtos);
-
Um cliente faz vários pedidos;
-
Um pedido tem vários itens;
-
Um item pertence a um produto;
-
Um pedido pode ser fechado por um vendedor;
-
Fato = evento (pedido, item do pedido);
-
Dimensões = contexto (cliente, produto, vendedor).
Agora vamos para o SQL completo (modelo físico)
A partir daqui, você verá como isso vira um banco de dados real.
1. Criando a tabela cliente
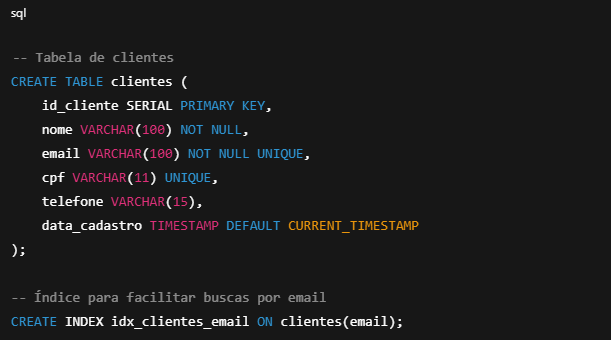
Por que assim?
– E-mail deve ser único;
– Data de cadastro é obrigatória;
– Nome pode mudar, mas ID nunca.
Para não ter dúvidas: os produtos são independentes e podem ser criados antes dos pedidos, sem nenhum problema.
2. Tabela produto

Por que assim?
– Preço precisa de decimal;
– Categoria é opcional;
– Nome sempre obrigatório.
Agora podemos criar pedidos, que dependem de clientes. Cada pedido está ligado a 1 cliente (relação 1:N).
3. Tabela vendedor

Por que assim?
– Nem todo vendedor tem departamento definido.
– ID autoincremento é padrão.
Agora falta conectar pedidos ao que realmente foi comprado → usamos a tabela itens_do_pedido.
4. Tabela pedido

Conexão com o negócio:
– Todo pedido tem um cliente.
– Nem sempre tem vendedor (pedidos automáticos, por exemplo).
5. Tabela itens do pedido
Essa tabela resolve o relacionamento N:N:
-
1 pedido pode ter vários produtos.
-
1 produto pode estar em vários pedidos.

Por que assim?
– O preço unitário é salvo no momento da compra (se o preço do produto mudar, o histórico não se perde).
– Quantidade nunca pode ser 0.
Transforme dados em decisões estratégicas
O conhecimento que você adquiriu aqui é fundamental, mas representa apenas o começo da jornada de um analista de dados completo. Dominar SQL e modelagem é essencial, porém o mercado procura profissionais que também saibam formular hipóteses de negócio, extrair insights relevantes e comunicar descobertas de forma convincente para stakeholders.
O curso Data Analytics da Tera oferece a formação completa que você precisa. São mais de 36 horas de conteúdo prático abordando SQL avançado, métricas de negócio, storytelling com dados e análise estratégica.
Você aprende com especialistas de empresas como Itaú, Mercado Livre e iFood, desenvolvendo projetos reais para seu portfólio.



