
A árvore de decisão é um dos algoritmos de Machine Learning mais populares e intuitivos, perfeito para quem está começando na área de ciência de dados. Neste artigo, você vai entender como funciona uma decision tree, quando usar, suas vantagens e desvantagens, e aprenderá a implementar com exemplos práticos em Python.
Ideal para classificação e regressão, este algoritmo é fundamental para qualquer cientista de dados. Vamos explorar desde os conceitos básicos até aplicações reais como diagnóstico médico, análise de crédito e previsão de churn. Se você busca dominar um dos pilares do machine learning supervisionado, este é o lugar certo para começar.
O que é árvore de decisão?
Uma árvore de decisão é um algoritmo de machine learning (aprendizado de máquina) supervisionado que é utilizado para classificação e para regressão. Isto é, pode ser usado para prever categorias discretas (sim ou não, por exemplo) e para prever valores numéricos (o valor do lucro em reais).
Estrutura básica: nó raiz, nós de decisão e folhas
Assim como um fluxograma, a árvore de decisão estabelece nós (decision nodes) que se relacionam entre si por uma hierarquia bem definida. Vamos entender cada componente:
-
Nó-raiz (root node): é o ponto de partida da árvore, o nó mais importante que representa o atributo com maior poder de separação dos dados;
-
Nós de decisão (decision nodes): são os pontos intermediários onde o algoritmo faz perguntas sobre os atributos dos dados;
-
Nós-folha (leaf nodes): são os resultados finais, as respostas ou previsões que o modelo oferece.
No contexto de machine learning, o nó raiz é um dos atributos mais relevantes da base de dados, e o nó-folha é a classe ou o valor numérico que será gerado como resposta final.
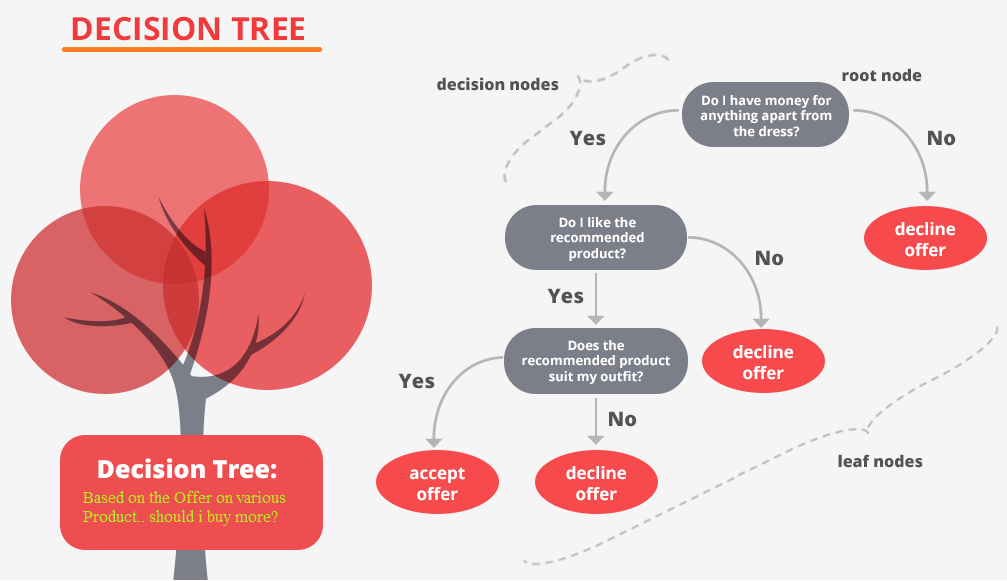
Como funciona o algoritmo na árvore de decisão?
Na ligação entre nós, temos regras de "se-então" (if-then rules). Ao chegar em um nó A, o algoritmo se pergunta acerca de uma regra, uma condição, como:
-
"Se a característica X do registro analisado é menor do que 15?";
-
Se for menor, então ele vai para o lado esquerdo da árvore;
-
Se for maior ou igual, então ele vai para o lado direito.
No próximo nó, segue a mesma lógica de questionamento e divisão.
É um algoritmo que segue o que chamamos de "recursivo" em computação. Ou seja, ele repete o mesmo padrão sempre na medida em que vai entrando em novos níveis de profundidade. É como se uma função chamasse a ela mesma como uma segunda função para uma execução paralela, da qual a primeira função depende para gerar sua resposta.

O grande trabalho da árvore é justamente encontrar os nós que vão ser encaixados em cada posição:
-
Quem será o nó raiz?
-
Depois, quem será o nó da esquerda?
-
E o da direita?

Para isso, é preciso realizar alguns importantes cálculos matemáticos. Uma abordagem comum é usar o ganho de informação e a entropia. Essas duas variáveis dizem respeito à desorganização e falta de uniformidade nos dados.
Entendendo a Entropia:
-
Quanto mais alta a entropia, mais caóticos e misturados estão os dados;
-
Quanto menor a entropia, mais uniforme e homogênea está a base;
-
A entropia zero significa que todos os dados pertencem à mesma classe (perfeita homogeneidade).
Para definir os posicionamentos dos nós, é preciso calcular a entropia das classes de saída e o ganho de informação dos atributos da base de dados. Quem tiver maior ganho de informação entre os atributos é escolhido como o nó-raiz. Para calcular os nós filhos à esquerda e à direita, deve-se realizar novos cálculos de entropia e ganho com o conjunto de dados que atende à condição que leva a cada lado.
Como falamos, para dividir a base de dados em uma árvore, dependemos das condições de divisão. A partir delas, dividimos a base em caminhos com análise dos registros que satisfazem determinada condição.
Exemplo prático:
-
Se uma condição for "idade ≥ 18" para o lado direito, teremos somente os registros da base que possuem idade maior ou igual a 18 anos.
-
Se a condição for "idade < 18" para a esquerda, teremos somente registros com idades menores que 18 para a esquerda.
O ganho de informação é calculado a partir dessa lógica. Se quando eu analiso um atributo, os registros das bases para cada lado são homogêneos ou próximos disso, temos um alto ganho de informação. Afinal, sabemos que se optarmos por determinada condição, é muito provável que saibamos exatamente a saída esperada ou estejamos mais próximos de descobrir.
Contudo, se o ganho for pequeno, isso quer dizer que os dados estão muito misturados e que, portanto, estamos mais distantes de descobrir as saídas esperadas com precisão.
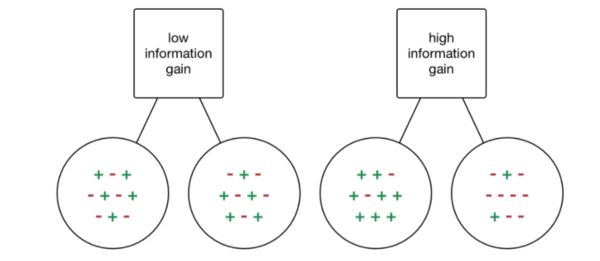
Fonte: TowardsDataScience
Passo a passo: como construir uma árvore de decisão
Para montar um algoritmo de árvore de decisão, é necessário utilizar bibliotecas auxiliares que trazem consigo implementações e configurações já prontas. Contudo, é preciso entender o que são os termos técnicos, como a entropia já citada. Afinal, essas informações são passadas como parâmetros para as funções prontas.
Entretanto, caso a pessoa queira aprender mais profundamente, ela pode tentar implementar sua própria árvore do zero. Isso pode ser feito com o cálculo da entropia das classes e do ganho de informação em funções recursivas. De certo modo, a função não é tão complexa quanto o funcionamento dela conceitualmente.

1. Cálculo da entropia
A entropia mede o grau de impureza ou desordem em um conjunto de dados. É calculada usando a fórmula:
Entropia(S) = -Σ (pi * log2(pi))
Onde:
- S é o conjunto de dados
- pi é a proporção de exemplos da classe i
- A soma é feita sobre todas as classes
Exemplo prático:
Se temos 10 exemplos, sendo 7 positivos e 3 negativos:
- p(positivo) = 7/10 = 0.7
- p(negativo) = 3/10 = 0.3
- Entropia = -(0.7 * log2(0.7) + 0.3 * log2(0.3)) ≈ 0.88
Quanto mais próximo de 1, mais misturados estão os dados. Quanto mais próximo de 0, mais puros (homogêneos).
2. Ganho de informação
O ganho de informação mede quanto uma divisão reduz a entropia. É calculado como:
Ganho(S, A) = Entropia(S) - Σ (|Sv|/|S| * Entropia(Sv))
Onde:
- S é o conjunto original
- A é o atributo usado para dividir
- Sv são os subconjuntos resultantes da divisão
- |Sv|/|S| é a proporção de exemplos em cada subconjunto
O atributo com maior ganho de informação é escolhido para fazer a divisão.
3. Critérios de Divisão: Gini vs Entropy
Existem dois critérios principais para decidir como dividir os nós:
Índice de Gini (Gini Impurity):
Gini(S) = 1 - Σ (pi²)
- Mais rápido de calcular (não usa logaritmo)
- Padrão na maioria das bibliotecas
- Valores entre 0 (puro) e 0.5 (máxima impureza em problema binário)
Entropia (Entropy):
Entropia(S) = -Σ (pi * log2(pi))
- Mais teoricamente fundamentada
- Pode resultar em árvores ligeiramente diferentes
- Computacionalmente mais cara
Na prática, ambos produzem resultados similares, e o Gini é mais usado por ser mais eficiente.
Como montar uma árvore de decisão em Python?
Nas duas principais linguagens de programação utilizadas em Data Science, Python e R, temos métodos bem fáceis e intuitivos para gerar esse algoritmo e conduzir classificação ou regressão sem problemas.
Árvore de Decisão em Python com Scikit-Learn
Você consegue implementar uma decision tree em apenas algumas linhas em Python. Pode usar, por exemplo, o módulo DecisionTreeClassifier, da biblioteca Scikit-Learn, com as funções fit, score para treinar e avaliar. Quando precisar classificar um novo registro e verificar se o modelo aprendeu realmente, utiliza-se o método predict.

Depois disso, a pessoa cientista pode inclusive utilizar funções do matplotlib para plotar um gráfico indicando visualmente como essa decision tree está realizando previsões. Isso vira um tipo de informação visual para compartilhar com outras pessoas, inclusive.
Árvores de decisão com R
No R, também conseguimos com muita facilidade construir um algoritmo de árvore decisória. Temos bibliotecas distintas como cTree, RPart e Tree. Em pouquíssimas linhas, podemos chegar à criação desse modelo. Também é possível visualizar de forma intuitiva. É interessante perceber que se usa também o método “fit” ou seja, o raciocínio não é tão diferente do Python.
4 Exemplos práticos de aplicação
Visto que você já entendeu como montamos uma árvore e como ela funciona na estruturação de sua hierarquia de nós, vamos avançar para aplicações práticas em cenários reais de negócio.
1. Diagnóstico médico
Uma decision tree pode ser aplicada para identificar doenças a partir de informações cedidas ao algoritmo como treinamento uma tarefa de classificação. Nesse caso, o sistema apreende os dados de sintomas, exames e histórico médico, entende suas relações, realiza os cálculos a fim de entender quais são os atributos mais importantes (nós) e ajusta as condições de divisão.
Exemplo prático:
-
Entrada: sintomas (febre, tosse, dor de cabeça), idade, histórico médico.
-
Saída: diagnóstico (gripe, COVID-19, resfriado comum, alergia).
A grande vantagem, como falamos, é o fato de que não é necessário se preocupar muito com o tratamento dos dados. Para resultados ainda mais interessantes e robustos, uma Random Forest (assembleia de árvores) deve ser adotada, reduzindo o risco de overfitting e aumentando a precisão geral.
2. Churn Prediction - Previsão de saída de clientes
Um uso muito específico e valioso é para o departamento de RH ou Customer Success saber quando um funcionário está quase saindo da empresa por insatisfação, ou quando um cliente está prestes a cancelar um serviço.
Exemplo prático - RH:
-
Entrada: satisfação no trabalho, salário, tempo na empresa, promoções recebidas, avaliações de desempenho.
-
Saída: risco de saída (Alto/Médio/Baixo).
Exemplo prático - Clientes:
-
Entrada: frequência de uso, reclamações, tempo como cliente, valor gasto, engajamento.
-
Saída: vai cancelar? (Sim/Não).
Com a análise de dados históricos sobre cada um, o modelo entende padrões de comportamento e consegue realizar uma predição (classificação) permitindo ações preventivas de retenção.
3. Análise de sentimentos em redes sociais (NLP)
Não é incomum ver também aplicações na área da análise de sentimentos, subcategoria do campo de processamento de linguagem natural (NLP). O modelo entende os dados textuais e tenta prever se um texto (comentário, review, tweet) deve ser categorizado como positivo, negativo ou neutro.
Exemplo prático:
-
Entrada: texto de review de produto, comentário em rede social.
-
Saída: sentimento (Positivo/Neutro/Negativo).
Aplicações comerciais:
-
Monitoramento de marca em redes sociais;
-
Análise de feedback de clientes;
-
Avaliação de reviews de produtos.
Para melhores resultados em NLP, a Random Forest ou modelos mais avançados como BERT são aplicados também, mas árvores de decisão simples servem como baseline excelente.
4. Segmentação de clientes para Marketing
Empresas usam árvores de decisão para segmentar clientes em grupos com comportamentos similares, permitindo campanhas de marketing mais direcionadas.
Exemplo prático:
-
Entrada: idade, renda, histórico de compras, localização, comportamento online.
-
Saída: segmento (Premium, Econômico, Ocasional, Frequente).
Vantagens neste caso:
-
A árvore mostra claramente quais características definem cada segmento;
-
Fácil de explicar para o time de marketing;
-
Permite criar personas baseadas em dados reais.
Da teoria à prática: transforme dados em decisões estratégicas
Dominar árvores de decisão é apenas o começo de uma jornada mais ampla em análise de dados. Se você trabalha com produtos digitais, entender como coletar, analisar e interpretar dados de comportamento dos usuários pode ser o diferencial.
E é exatamente por isso que o Product Analytics se tornou uma competência indispensável para gerentes de produto, analistas de dados e líderes que precisam argumentar suas decisões com dados reais.
Então, o seu próximo passo para é dominar o universo do Product Analytics de forma estruturada e prática.



