
O Naive Bayes é um algoritmo para aprendizado de máquina que gera uma tabela de probabilidades. Saiba mais sobre o assunto.
Um dos mais tradicionais e importantes algoritmos de aprendizagem de máquina, o Naive Bayes é um grande destaque tanto entre os acadêmicos quanto no mercado. Trata-se de uma solução simples para problemas de classificação, que oferece um ótimo embasamento estatístico para as ações de machine learning (ML).
Assim, quem pesquisa e estuda esse segmento precisa dominar o conceito e seu funcionamento. O Naive Bayes é também uma boa maneira de começar na área para aprofundar posteriormente com soluções mais robustas. É essencial para pessoas cientistas de dados de todos os níveis. Saiba mais sobre o tema a seguir.
O que é o algoritmo Naive Bayes?
O classificador Naive Bayes é um algoritmo que se baseia nas descobertas de Thomas Bayes para realizar predições em aprendizagem de máquina. O termo “naive” (ingênuo) diz respeito à forma como o algoritmo analisa as características de uma base de dados: ele assume que as features são independentes entre si.
Além disso, ele também assume que as variáveis features são todas igualmente importantes para o resultado. Em cenários em que isso não ocorre, essa técnica deixa de ser a opção ideal. Discutiremos adiante sobre as aplicações.
Como Bayes é um nome famoso na estatística, é fácil concluir que o seu algoritmo tem uma forte base dessa área, reforçando a relação entre estatística e inteligência artificial.
Inclusive, o seu funcionamento pode ser facilmente descrito em termos estatísticos: para calcular a predição, o algoritmo define, primeiramente, uma tabela de probabilidades, em que consta a frequência dos preditores com relação às variáveis de saída. Então, o cálculo final leva em conta a probabilidade maior para oferecer uma solução.
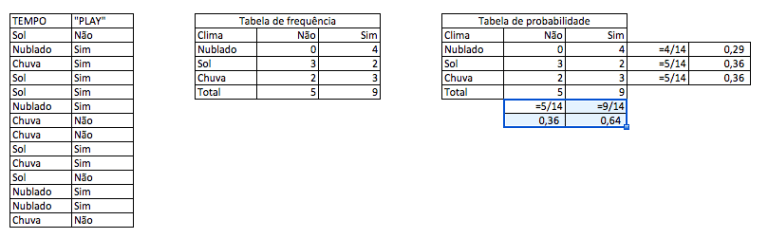
Fonte: Voo
Duas características importantes do Naive Bayes: seu desempenho também é consideravelmente bom com classes múltiplas e ele funciona melhor com features categóricos (palavras) do que com numéricos.
Entendendo um algoritmo de classificação
Em machine learning, chamamos de algoritmo de classificação o que busca oferecer uma resposta que está entre opções predeterminadas. Como dizer se alguém tem uma doença ou não: o escopo é limitado a duas opções (sim ou não).
É diferente, por exemplo, de um problema de regressão, que estima um valor numérico, ou de um problema de clusterização, que define subgrupos para os dados.
Além disso, o problema de classificação se encaixa na categoria de problema supervisionado, pois gera uma predição e um modelo como resultado, sendo necessária a supervisão de profissionais. Ou seja, quem treina passa os dados e as saídas dos dados de treinamento, informando ao sistema exatamente o que ele deve aprender.
Outro algoritmo famoso de classificação é a árvore de decisão. Ela analisa os dados, faz diversos processamentos para definir nós e uma hierarquia e, então, gera uma árvore como modelo.
O contrário disso seria um algoritmo descritivo, não supervisionado, que busca descrever a relação já existente entre os dados, como as regras de associação. Nesse caso, não se passa saídas predeterminadas e o sistema vai descobrindo os dados por si só.
Uma solução de classificação tenta entender os padrões dos dados para aprender como cada saída surge. Ele segue um caminho mais curto por conta da supervisão.
Naive Bayes e Machine Learning: qual a relação?
Além de suas contribuições para a estatística, Bayes também gerou uma grande ajuda ao universo do Machine Learning. O classificador Naive Bayes é um dos principais algoritmos da área, sendo para muitas pessoas o primeiro contato com esse universo. A fórmula do classificador determina apenas os passos a serem seguidos para o aprendizado.
Por ser mais simples e envolver uma base estatística fácil de entender, ele é o preferido em muitos casos.
Um dos destaques do uso é o fato de que é fácil ilustrar também. Se você pegar uma base de exemplo pequena, pode fazer os cálculos e seguir o procedimento do algoritmo.
Além disso, o Naive também é usado, especificamente, para alguns tipos de problemas de ML supervisionado, como veremos.
Quando usar Naive Bayes?
Um dos problemas mais clássicos para ilustrar como o Naive Bayes é importante é o classificador de spam. Ele analisa e-mails e tenta avaliar se ele é spam ou não (classes definidas) com base em suas informações e em estrutura. É um problema de processamento de linguagem natural, portanto.
Nesse universo, temos também classificadores de sentimento. Nesses casos, eles analisam os textos e tentam identificar a emoção expressada, geralmente entre opções específicas como “neutro”, “positivo” ou “negativo”.
Contudo, as aplicações não param por aí. Há usos de Naive Bayes para aplicações de Data Science na saúde, como sistemas que determinam se alguém tem uma doença ou não.
Também é possível encontrar versões do algoritmo em sistemas de recomendação, como filtragem colaborativa e outros. Nesse caso, o objetivo é analisar certas pessoas e tentar sugerir algo que possa interessar a elas, seja conteúdo, seja produtos.
Como já falamos, o classificador é extremamente versátil. Contudo, ele não se aplica para projetos mais complexos. Para variáveis numéricas, pode ser mais interessante usar outra técnica. Em alguns cenários de dados massivos, a necessidade é por soluções de Deep Learning, como as complexas redes neurais, para melhor desempenho e melhor acurácia.

Aprenda esse e outros algoritmos de Machine Learning
Para saber mais sobre o algoritmo Naive Bayes e tantos outros do universo de Machine Learning, é sempre muito bom estudar de forma organizada. O Curso de Data Science e Machine Learning da Tera, por exemplo, oferece aos estudantes a possibilidade de evoluir na área, indo dos assuntos mais básicos aos mais complexos.
Tudo isso com a ajuda e a mentoria de tutores renomados dentro da área, a possibilidade de fazer networking com outras pessoas e os projetos práticos que ajudarão a tirar os conteúdos do papel. Você terá uma boa base teórica e saberá como isso se aplica em contextos reais para alcançar o melhor dos dois mundos. Dessa forma, você consegue evoluir e desenvolver suas habilidades para alcançar vagas no mercado.
O Naive Bayes é um algoritmo fortemente baseado em estatística. Com base em análises de frequências e relações entre as variáveis features e as de saída, ele consegue aprender sobre os dados e fazer predições inteligentes. Desse modo, profissionais de Data Science são capazes de solucionar problemas de classificação com uma técnica simples e fácil de compreender.
Gostou do conteúdo? Não perca a chance de evoluir nesse universo rico e conheça o Curso de Data Science e Machine Learning da Tera.


