
A clusterização é uma técnica importante para definir agrupamentos entre dados similares. Conheça mais sobre o conceito.
Photo by Surface on UnsplashA clusterização é um robusto método de análise para machine learning e para projetos de Data Science. Ele avalia os dados e tenta encontrar alguns padrões sem a base da supervisão, como no caso de outros algoritmos. Desse modo, torna-se poderoso para extrair alguns insights gerais que ajudam as empresas na tomada de decisões.
O termo “cluster” refere-se a grupos. O algoritmo pensa em termos de dividir os dados em determinados agrupamentos, permitindo ações que alcancem todos os membros desses conjuntos. Existem várias técnicas usadas para definir esses grupos, sendo preciso conhecer cada uma delas para entender qual é a ideal para cada contexto.
Se quiser saber mais, confira com atenção os tópicos abaixo.

O que é clusterização?
A clusterização é uma técnica de machine learning não supervisionado que visa agrupar os dados em determinados conjuntos distintos entre si. É muito útil para diversos contextos, como para o marketing e para estudos de mercado. Trata-se de um método descritivo, pois apenas realça as características dos dados de entrada, sem intenção de realizar previsões ativas sobre eles.
As soluções que definem os clusters buscam determinar muito bem onde um agrupamento começa e onde termina, ou seja, com “contornos” muito bem estabelecidos. A principal característica é que os conjuntos são diferentes entre si, mas têm elementos com algum aspecto em comum — como a proximidade no gráfico.
Aliás, falando em gráfico, precisamos ressaltar que esse tipo de algoritmo é fortemente marcado pela sua representação gráfica. As técnicas são facilmente compreensíveis se considerarmos um plano de duas dimensões e dispormos os dados da base de entrada neles, conforme os valores de cada eixo.
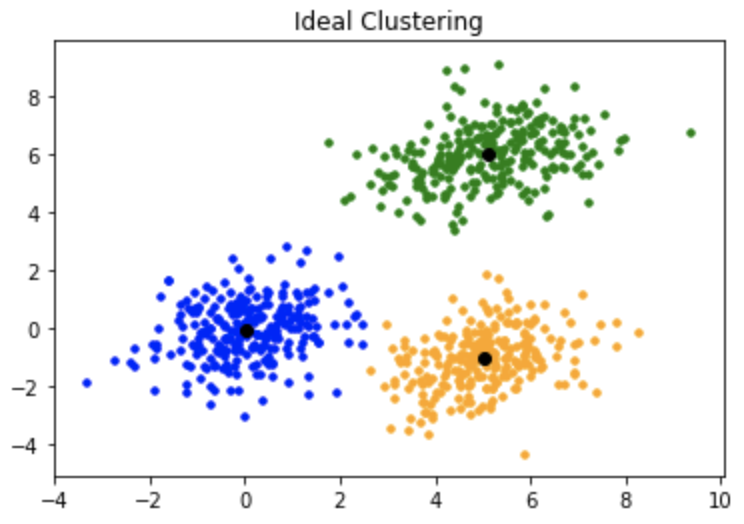
Fonte: Geeks for Geeks
O fator não supervisionado dessa técnica diz respeito, especificamente, à forma como os dados são passados. As informações de entrada são transmitidas sem qualquer tipo de rótulo predeterminado de saída — como nos modelos supervisionados. Dessa forma, é dever unicamente do sistema identificar os insights escondidos.
Aplicações
Na prática, observamos diversas finalidades para clusterização. Uma delas é a segmentação de clientes. O sistema analisa a base de dados dos consumidores e define grupos com os similares, inspirando ações específicas de comunicação para cada conjunto.
Podemos ter conjuntos com hábitos semelhantes ou que compram tipos de produtos semelhantes. Então, o marketing deverá tratar cada grupo de forma personalizada, de modo a atingir melhor cada consumidor e maximizar a lucratividade.
Os sistemas de recomendação também se baseiam muito em táticas de clusterização de dados. A partir da divisão dos clientes em determinados grupos, é possível sugerir a um elemento do grupo o que outro já consumiu. Em outros cenários, criam-se grupos de produtos, em que cada um dos elementos pode ser recomendado a clientes similares.
Outros usos são para agrupamento de resultados de pesquisa e para análise de redes sociais. Esse último, em específico, destaca-se por possibilitar uma visão de clientes similares ou de tópicos mais falados, por exemplo. Contudo, o céu é o limite: esses agrupamentos podem ser o que a pessoa cientista desejar.
Pode não ser incomum ver essas soluções aplicadas para identificar anomalias e outliers. O raciocínio é o seguinte: ao analisar os grupos de elementos similares, o algoritmo consegue destacar aqueles componentes que não puderam ser agrupados, o que viabiliza uma ação específica para tratar com eles.
Como funciona a clusterização de dados?
Ok, vamos à parte técnica. Nesta seção, você entenderá como funcionam os algoritmos de clusterização de dados.
Tudo começa com dados de entrada. Ao analisar os dados, o algoritmo geralmente os processa como em uma disposição no eixo cartesiano. Então, são feitos diversos cálculos para entender como estabelecer parentesco e similaridade entre cada registro isolado, normalmente a partir de diferentes visões de como captar a menor distância.
Isso porque é possível estabelecer parentesco entre dados analisando um-por-um ou um-para-vários. Essa questão depende das técnicas.
Os cálculos variam a depender do tipo de clusterização que é adotado. Veremos, a seguir, alguns tipos:
- modelos de conectividade;
- modelos de centróide;
- modelos de distribuição;
- modelos de densidade.
Modelos de conectividade
Os modelos de conectividade, geralmente, começam demarcando todos os dados como clusters únicos. Então, a partir disso, ele agrupa determinados clusters com base em distância menor. A ideia mais comum é a de uma hierarquia de grupos, em que um grupo geral de todos os registros é composto por pequenos grupos de elementos mais próximos uns aos outros.
O agrupamento hierárquico é um dos tipos mais conhecidos. Ele define uma árvore a partir dos agrupamentos e de suas relações. Desse modo, estabelece relações que perpassam todos os dados, mas que se especificam em subgrupos. Então, o raciocínio de análise permite descobrir, por si só, o número ideal de clusters.
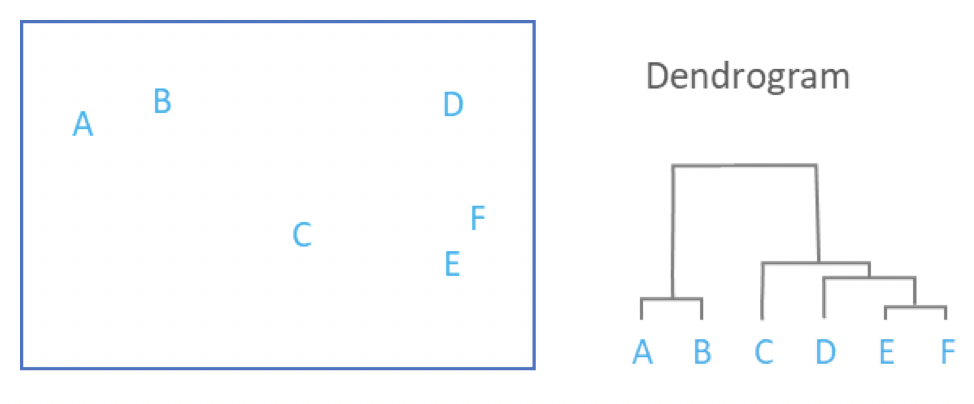
Fonte: Displayr
Modelos de centróide
O algoritmo que se baseia pela análise de centróide começa com a definição de pontos aleatórios no meio dos dados. Então, ele verifica quais elementos estão próximos daqueles centróides e os agrupa. Depois disso, ele reinicializa novos centróides, a partir de cálculos envolvendo os componentes. É uma técnica iterativa, portanto.
Um dos mais famosos é o K-means. Um fator importante acerca desse algoritmo é que a pessoa cientista de dados é quem define o número de clusters que ela necessita, o que requer um conhecimento maior do negócio ou dos dados analisados.
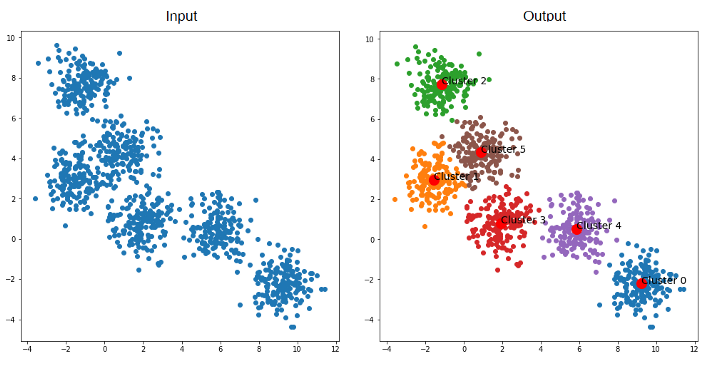
Fonte: Ichi
Digamos que você vá analisar dados de clientes que compram produtos. Você pode requisitar ao algoritmo dois clusters, pois você sabe por conhecimento sobre aquele nicho que só são vendidos dois tipos diferentes de produtos. Caso deseje segmentar mais, pode se ater a especificidades e determinar mais clusters em outra análise.
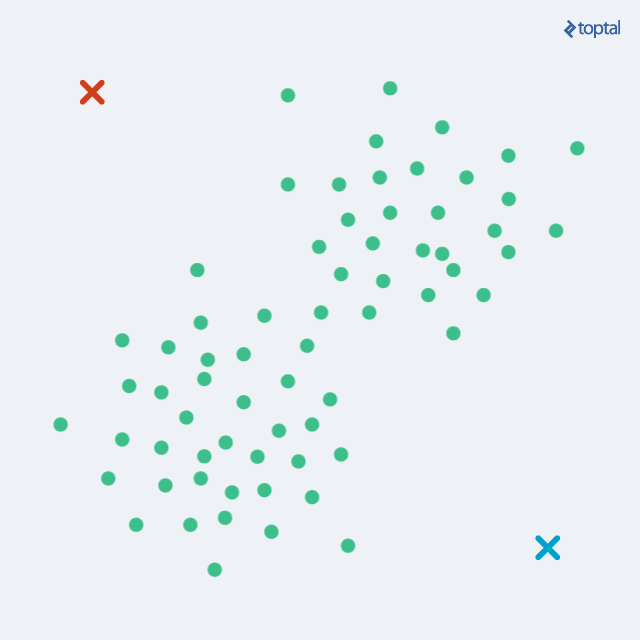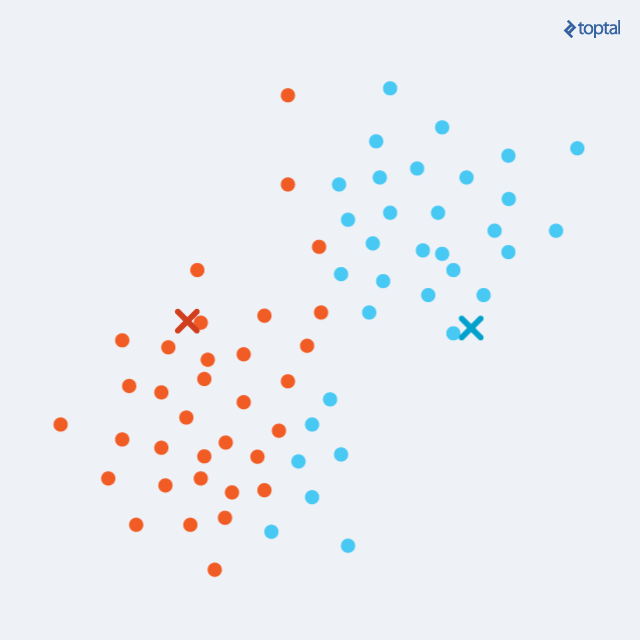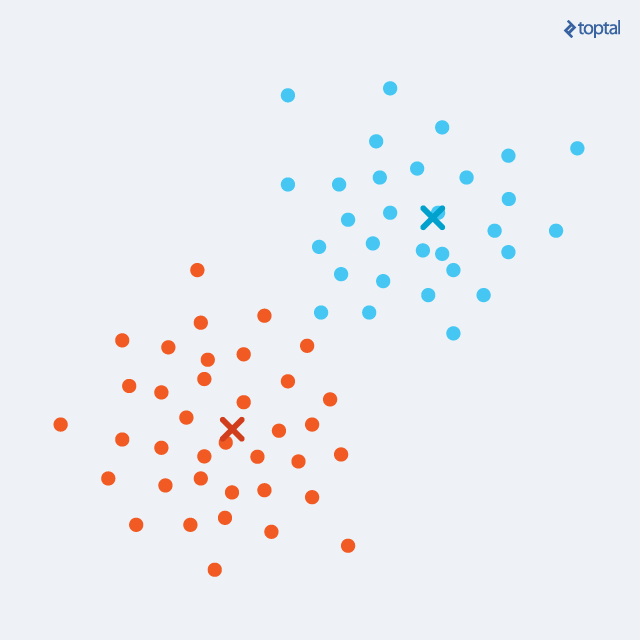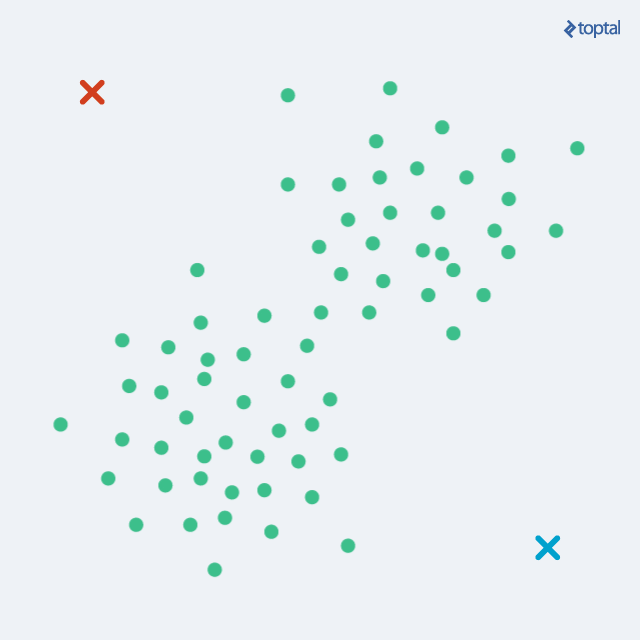
Fonte: Toptal
Modelos de distribuição
Os modelos de distribuição trabalham com a probabilidade de um elemento pertencer a um grupo ou não, com base, evidentemente, na distância. Desse modo, ele consegue reduzir outliers ao fornecer uma precisão maior para lidar com a incerteza de componentes mais distantes. Então, cabe à pessoa cientista determinar o grau de precisão que ela precisa para suas análises.
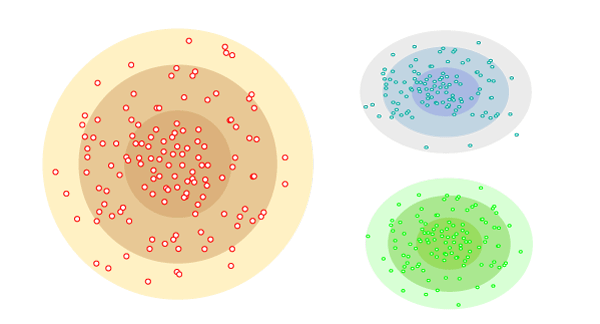
Fonte: Javatpoint
Modelos de densidade
Os modelos de densidade consideram a densidade das regiões do gráfico para avaliar a possibilidade de criar grupos com similares. O DBScan, por exemplo, é um famoso exemplo. Ele estabelece círculos que pegam todos os elementos dentro do raio de análise, sendo que o raio é um valor determinado previamente. A partir disso, ele reinicia o círculo a partir do registro com a menor distância do ponto inicial e vai agrupando.
Quando o círculo não pega mais nenhum registro dentro do seu raio, então o algoritmo para e determina aquele grupo como um cluster. Em seguida, começa de novo aleatoriamente e define outros clusters. O número de clusters é especificado pelo próprio DBScan, sem intervenção humana.
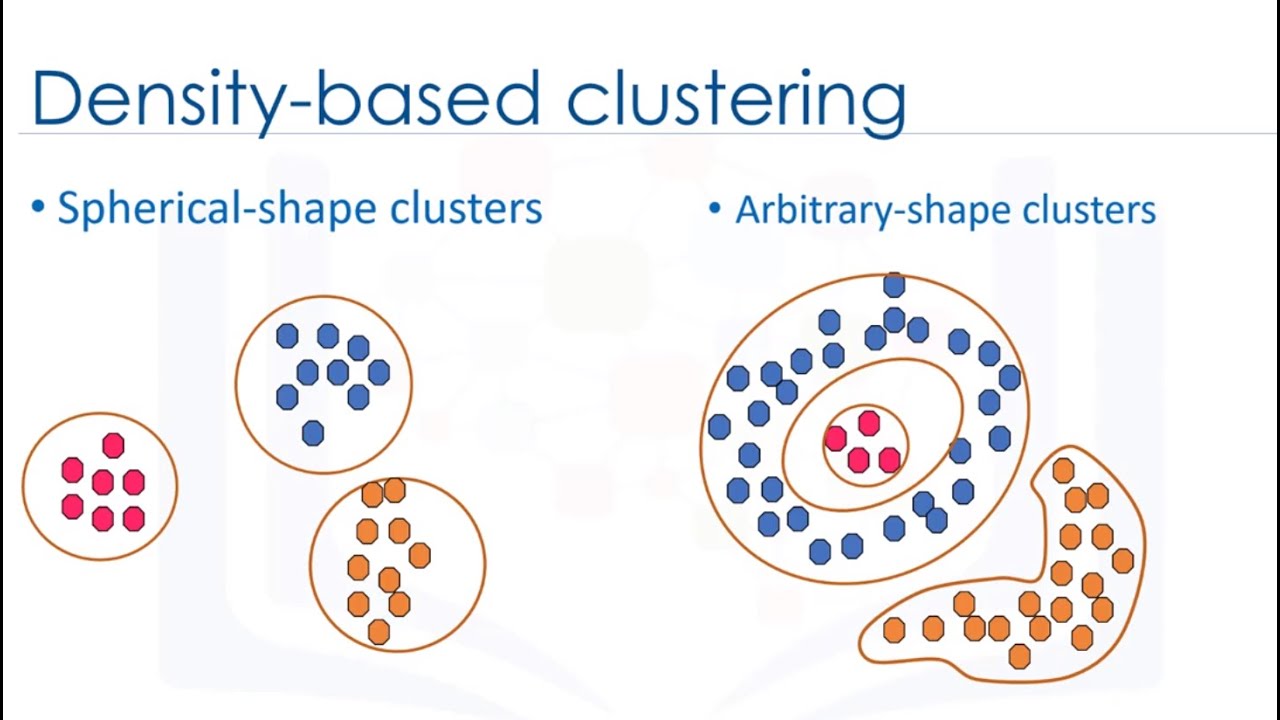
Fonte: YouTube
Qual a diferença entre classificação e clusterização?
Nesta importante seção, vamos analisar a diferença principal entre classificação e clusterização, que são métodos similares em alguns aspectos. Quem está estudando pode se confundir entre os dois, e isso é normal.
Os dois definem classes para seus dados. A classificação agrupa os dados em determinadas categorias, ao passo que a clusterização utiliza a noção de clusters.
Contudo, a principal diferença é a supervisão. A classificação é um clássico método supervisionado, em que o número de categorias para os dados é definido de antemão, com base nos dados de entrada. Ou seja, a pessoa cientista transmite dados com os rótulos prévios de saída, solicitando que o sistema aprenda como aqueles dados geram aquelas saídas.
Para testar um classificador, é muito simples: basta usar um dado de entrada, cuja saída já era dada, como uma informação nova, a ser classificada. Então, o algoritmo deve determinar a mesma saída que já estava proposta.
Um preditor de spam, por exemplo, terá um registro de entrada que é um e-mail com características de spam, marcado como spam na base de dados. Você então faz uso dele para checar se o modelo vai realmente classificar como spam.
Para isso, as pessoas da área dividem os dados rotulados do dataset entre dados de treinamento e dados de teste.
Por outro lado, a clusterização é feita sem supervisão, como vimos. Não há rótulos, nem mesmo elementos esperados de antemão. Nesse sentido, não há uma noção de testagem com comparação, como nos outros modelos. Os resultados que saem são os insights que o algoritmo está sugerindo.
Em outros termos, a classificação é uma técnica preditiva, pois seu objetivo é classificar novos registros que serão passados. A partir de um treinamento com bases de dados de crédito, você chega a um modelo que consegue determinar se um cliente que acabou de chegar no banco vai honrar um empréstimo ou não.
Já a clusterização é uma técnica descritiva. Seu propósito é puramente estabelecer as relações já existentes: ressaltar quais são os registros mais próximos em termos de distância. Você consegue definir o número de clusters para uma visão mais segmentada em algumas soluções (como o K-means), contudo, o algoritmo apenas olha para os dados e devolve o que já está neles.
Além disso, em uma base de dados comercial, que é muito grande, é normal que você tenha vários clusters. Uma base de clientes de uma varejista grande, por exemplo, vai gerar diversos subgrupos de consumidores relacionados aos produtos e no perfil. Mesmo que você escolha menos clusters, o número de grupos que é possível criar depende fortemente do número de elementos no dataset.
Já a classificação busca delimitar um registro novo em classes específicas, geralmente com um número menor. Problemas clássicos de classificadores, como a classificação de e-mails como spam, são baseados em apenas duas classes (é ou não), independentemente da quantidade de e-mails.
A clusterização é uma técnica muito usada em projetos de Data Science e Machine Learning para segmentação de clientes, divisão de produtos, análises de redes sociais, visualização de dados e outros fins. A pessoa cientista de dados precisa conhecer essas soluções, pois elas são extremamente importantes para diversas necessidades do dia a dia.
Gostou deste conteúdo? Entenda melhor o perfil da profissão de cientista de dados!


