
Se você está começando em Data Science ou Machine Learning, já deve ter se deparado com o termo dataset. Mas afinal, o que é um dataset? De forma simples, é o combustível essencial para alimentar algoritmos e gerar insights.
Neste artigo, você vai entender para que servem os datasets, como usá-los e, o mais prático: vamos listar 10 fontes confiáveis e gratuitas para você baixar bases de dados e começar seus projetos agora mesmo, incluindo opções de datasets brasileiros.

O que são datasets?
Os datasets são bases de dados específicas que servem de amostras para treinamentos de algoritmos de inteligência artificial ou para outros tipos de projetos de Data Science. São bases geralmente dispostas em formato tabular, com linhas e colunas bem definidas e organizadas com informações claras acerca de sua finalidade.
Estrutura e formatos comuns de um dataset
O formato de um dataset varia entre CSV, TXT, XML, JSON e até XLS. Especificamente, os dados de um dataset podem ser usados para treinamento de um algoritmo de machine learning que vai prever alguma informação, como também pode ser base para a visualização de dados com gráficos e relatórios que descrevem a base e extraem insights de forma mais direta.
Esses dados são importados e processados com as bibliotecas e funções específicas da linguagem utilizada. Em Python, temos a biblioteca Pandas, que lida com especificações de datasets e possui vários recursos já prontos para a utilização. Um ponto facilitador acerca dos datasets é que em uma linha, podemos ter, por exemplo, o número do registro, e nas colunas, as características.

Os principais desafios: limpeza e tratamento de dados
Contudo, um dos desafios é que muitos dados nessas linhas e colunas apresentam inconsistências que atrapalham a análise. Exemplos comuns incluem:
-
Dados faltantes: campos vazios que precisam ser preenchidos ou removidos;
-
Dados inválidos ou errados: informações que não seguem o padrão esperado;
-
Dados duplicados: registros repetidos que podem interferir na qualidade da análise.
Nesses casos, é preciso submeter o dataset a uma sessão de limpeza e tratamento antes de usar os algoritmos específicos para treinar o sistema. Esse processo é essencial para garantir a qualidade dos resultados em projetos de machine learning e análise de dados.
Dataset vs. Database: qual a diferença?
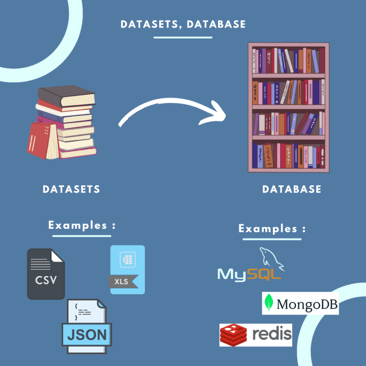
Com a definição que normalmente damos para dataset, existe uma clara confusão com a concepção de banco de dados (database), que é mais clássica. No universo de TI, falamos muito em datasets recentemente por conta da explosão dos dados e da evolução da inteligência artificial. Por sua vez, o conceito de banco de dados existe há muito tempo, como um suporte para sistemas de processamento de dados.
Tabela comparativa: Dataset vs. Database
| Característica | Dataset | Database |
|---|---|---|
| Tamanho | Amostra menor e específica | Base maior e abrangente |
| Finalidade | Análise, treinamento de IA | Armazenamento para aplicações |
| Escopo | Dados finitos com prazo definido | Dados contínuos e crescentes |
| Propriedade | Geralmente público ou compartilhado | Privado da organização |
| Uso principal | Data Science e Machine Learning | Sistemas web, mobile e desktop |
Principais diferenças:
-
Dataset é uma amostra menor do que um database. É uma amostra específica para algum projeto, com uma relação muito clara entre os dados. Como um conjunto de dados de pessoas que foram vacinadas em um dado período ou o número de vendas de uma loja em todas as suas filiais em um ano.
-
Databases são bases maiores que representam a modelagem da realidade e dos relacionamentos entre elementos da realidade. Um banco de dados de uma rede social, por exemplo, contém os cadastros das pessoas, as informações de perfil e dados relacionados às conexões de cada perfil com outros perfis.
Um CRM é outro bom exemplo de um banco de dados. Nele, estão dispostos os dados de todas as pessoas consumidoras de uma empresa que entraram em contato ou interagiram em algum momento. É uma estrutura maior que guarda os dados completos para atender ao objetivo daquela determinada aplicação.

Como encontrar o dataset ideal para seu projeto?
Antes de começar um projeto de desenvolvimento de Data Science ou machine learning, as pessoas geralmente passam por um processo de busca dos datasets ideais. Para isso, é preciso atender a alguns critérios de procura.
Critérios importantes na escolha do dataset:
-
Idioma e contexto: temos datasets brasileiros e vários outros datasets em outros idiomas (principalmente em inglês). A vantagem do dataset ser nacional é não conter termos específicos de segmentos que a pessoa cientista desconhece.
-
Formato dos dados: essas plataformas oferecem dados em formato CSV, JSON, PDF e outros. Verifique se o formato é compatível com suas ferramentas.
-
Documentação: a presença de documentação explicando as colunas e as características facilita muito o trabalho (embora essa documentação nem sempre esteja disponível).
-
Qualidade dos dados: avalie o nível de limpeza necessário e a confiabilidade da fonte.
10 fontes de datasets para usar nos seus projetos em 2026
Agora, vamos efetivamente conhecer as melhores opções de sites para encontrar datasets de machine learning, deep learning e visualização de dados.
1. Dados.gov
Seguindo uma proposta de trazer mais transparência para as ações governamentais e para os registros públicos, o site “Dados.gov.br” (Portal Brasileiro de Dados Abertos) reúne dados de diferentes instâncias para análise. É possível encontrar informações sobre ministérios específicos, como o da Fazenda, estados, setores específicos, bem como órgãos e instituições como IBGE, INSS, Banco Central.
Além disso, você encontra informações específicas sobre o censo da população e sobre as pessoas que estão cadastradas em programas sociais, como o Bolsa Família. Os dados estão dispostos em diversos formatos, tais como PDF e XML, e envolvem dicionários para explicar como funcionam.
2. Banco Central do Brasil
Além do Data.gov, se a pessoa cientista de dados ou estudante quiser dados específicos acerca do sistema financeiro e bancário, pode encontrá-los no portal do Banco Central. São dados das instituições autorizadas pelo BC, que estão lá com o objetivo de gerar maior transparência.
3. Google Analytics
No Google Analytics, encontramos dados analíticos sobre as visitas a um site, como:
-
número de sessões;
-
dispositivos usados;
-
navegadores usados, entre outros.
É possível estabelecer filtros por dia, por mês, por semana ou por ano. O interessante é que você conta com dados em um formato gráfico, já com formas eficientes de visualização.
4. Portal da transparência
Outro bom exemplo de dataset brasileiro é o Portal da transparência, um registro acerca de investimentos públicos, despesas e ganhos das instituições. Você pode usar como um complemento ao data.gov.
5. Reddit
Um dos fóruns mais famosos da internet, o Reddit apresenta várias vantagens que poucas pessoas conhecem. Uma delas é o repositório para cientistas de dados que contém diversas discussões úteis sobre questões da área.
Além disso, existe uma seção específica para datasets de diversas qualidades e tipos. A pessoa pode ainda conferir os comentários acerca deles para saber se são ideais para o que procura.
Atualmente na base do Reddit você encontra datasets bem relevantes, como alguns sobre a empresa Uber, sobre a pandemia de Covid-19, sobre fake news, etc.
6. Kaggle
O Kaggle provavelmente é o mais famoso site para cientistas de dados. Contém diversos projetos e desafios que uma pessoa pode tentar superar em busca de prêmios. Além disso, é uma comunidade para pessoas da área se ajudarem em projetos.
O site também traz inúmeras opções de datasets para auxiliar no desenvolvimento de modelos inteligentes e aplicações de visualização.
Você consegue facilmente encontrar o que precisa com filtros e até mesmo encontrar uma documentação que ajuda bastante a compreender o que cada coluna significa.
7. FiveThirtyEight
Outra plataforma muito conhecida por pessoas da área é o FiveThirtyEight. É um site que desenvolve alguns projetos envolvendo Data Science e também oferta diversas boas opções de datasets.
No portfólio deles, encontram-se datasets sobre filmes, tendências do momento, eleições presidenciais, esportes e outros assuntos bem diversos.
8. Repositório de Machine Learning da UCI
Outro site bastante famoso é o repositório de ML da UCI. São conjuntos de dados geralmente de boa qualidade, fornecidos pelas próprias pessoas usuárias. Os tópicos encontrados variam bastante, de e-mails com rótulos de spam para classificações a questões ambientais.
O mais legal sobre as bases da UCI é que a plataforma distribui os sets para cada tipo de problema (classificação, regressão ou associação, por exemplo). Ademais, existem divisões por tipos de dados (nominais ou numéricos), formatos e outras características. Essa filtragem já ajuda no processo de escolha dos sets ideais.
9. Amazon Reviews
Para quem busca por datasets na área de processamento de linguagem natural (NLP), existe um site da Stanford com bases de reviews de produtos no site da Amazon, divididos pelo segmento do produto analisado por clientes. Trata-se de uma base bem grande para projetos bem interessantes.
10. Google Dataset Search
A gigante das buscas tem um motor específico para datasets, assim como o motor das imagens e o acadêmico. São mais de 20 milhões de datasets que podem ser encontrados a partir das buscas, com dados do site de hospedagem e da pessoa que publicou aquele set.
Do dataset ao produto: sua jornada em IA começa aqui
Ao longo deste artigo, vimos que os datasets são muito mais do que simples tabelas de dados: eles são a base fundamental que alimenta, treina e valida qualquer sistema de inteligência artificial. Desde a escolha do tipo correto supervisionado e não supervisionado.
Mas transformar esse conhecimento em soluções reais exige ir além. No curso AI Product Builders, você aprenderá a integrar datasets a produtos completos de IA, combinando seleção de dados, implementação de agentes autônomos, automação de fluxos e governança habilidades essenciais para criar soluções inteligentes que geram impacto real.
Comece agora a construir o futuro com IA!
-1.jpg?width=640&height=400&name=unnamed%20(4)-1.jpg)


