
Modelos estatísticos são essenciais para predições que geram valor e otimizam as decisões do negócio. Veja porque cientistas de dados precisam compreender o tema.
A estatística e a ciência de dados andam lado a lado. A estatística é um dos fundamentos matemáticos imprescindíveis para a atuação da pessoa cientista de dados e é, portanto, um requisito essencial para o currículo de quem se dedica à área (assim como a álgebra linear também).
Nesse sentido, é importante entender exatamente como essa relação se dá e o quão relacionados são esses campos do conhecimento.
A partir disso, profissionais de dados conseguem exercer seu trabalho com sucesso, com a análise de dados de diversas origens e criação de modelos estatísticos para encontrar informações de valor que auxiliem na tomada de decisão internamente.
Neste artigo, nossa proposta é explicar melhor a relação entre essas áreas e demonstrar como é possível criar modelos a fim de gerar valor para um negócio de maneira concreta. Confira!
Entendendo a relação entre Estatística e Ciência de Dados
A estatística é um dos pilares da Ciência de Dados. Ela fornece os instrumentos teóricos para que a Data Science opere e consiga chegar a seus resultados. Por isso, cabe à pessoa cientista entender bem esse campo pilar e saber como manipular diversos conceitos relevantes da área.
Em um projeto típico de Data Science, que começa com a análise de um problema, a estatística atua em diferentes etapas. Primeiro, você fará uso de muitos princípios da chamada estatística descritiva na fase de entendimento inicial dos dados e na análise exploratória. Por exemplo, tentar estimar a média em uma variável da base de dados importada.
Nesse caso, podemos mencionar também a capacidade de visualização de dados, que utiliza diagramas para representar os termos que estão presentes na Estatística. Um histograma, por exemplo, é a representação visual de um conceito chamado de distribuição de frequências.
Leia também: Visualização de dados: você já desenvolveu essa habilidade?
Em seguida, na fase de modelagem ou análise com algoritmos de inteligência artificial, a estatística também está onipresente. Primeiro, ela é a base de técnicas de machine learning supervisionado (com intervenção humana para o treinamento), como o classificador naive-bayes e a regressão linear.
Segundo, ela aparece em algum momento em outros métodos, sendo inclusive crucial para avaliar a precisão e acurácia de modelos.
No próximo tópico, vamos avançar nessa compreensão com a ideia de modelos estatísticos.
Criando modelos estatísticos para amparar decisões de negócio
Um modelo estatístico é uma representação da realidade na qual definimos a relação entre variáveis para entender e prever o comportamento de um fenômeno. Estabelecemos quais serão as variáveis independentes e qual será a variável dependente; a partir dos elementos independentes, tentamos prever um valor para o elemento dependente.
Na matemática, o modelo pode ser explicado com uma equação. De um lado da equação, o que queremos prever; do outro, o que já temos. Por exemplo:
-
y=4x³+5⁴
Quando chegamos ao conceito de modelagem estatística, a relação entre esse campo e a ciência de dados se torna ainda mais profunda. Afinal, os modelos ajudam as pessoas cientistas de dados a preverem um resultado para o problema em análise.
Pode ser, por exemplo, a necessidade de classificar se uma pessoa está apta a receber um empréstimo ou não do banco. Podemos, então, passar para o algoritmo uma base de dados com diversas características (variáveis independentes) e tentaremos traçar uma resposta binária, sim ou não (variável dependente).
Ainda na ideia de aprendizado supervisionado, temos um método clássico que ajuda a entender perfeitamente como estatística e ciência de dados andam lado a lado: a regressão linear. Por mais que seja uma técnica estatística, o conceito também ficou consagrado como uma forma de realizar previsões em Data Science, com uma característica específica: o fato de que prevê um número.
Ou seja, a regressão é um tipo de aprendizado supervisionado, pois envolve treinamento com suporte humano, assim como a classificação. Contudo, se a classificação quer prever em qual das categorias específicas vai se encaixar um novo registro, a regressão estima um valor único. No nosso caso fictício, seria a quantia que pode ser dada como empréstimo a esse cliente X no banco.
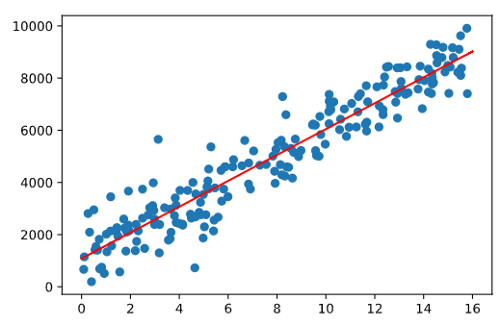
Fonte da imagem: Data Hackers
A regressão linear busca gerar uma reta no plano que melhor se adapta aos dados existentes na base. Ou seja, tenta traçar uma reta que identifica a tendência dos dados e tenta se adaptar a eles com o menor erro possível. Para chegar a essa reta, é preciso verificar as características dos atributos passados no treinamento e calcular alguns coeficientes.
Para entender a regressão, precisamos ter uma visão solidificada da representação visual dos dados em um plano de duas dimensões, um gráfico. E isso é uma noção muito própria da estatística em si.
Sugestão de leitura: Se você quer entender mais sobre regressão linear e aprender de forma prática, leia também o artigo de Beatriz Yumi, que é mentora no curso Data Science e Machine Learning da Tera.
Evidentemente, no dia a dia, a pessoa cientista de dados não precisará fazer cálculos de retas e outros tipos de processamentos de base. Eles já estão todos calculados nas bibliotecas e funções prontas. Contudo, cabe a cada profissional conhecer o método, entender como ele funciona e se vale aplicá-lo a um determinado problema.
Conceitos que são utilizados em ambas as áreas
Além da importante noção de modelo e modelagem, temos outras terminologias fundamentais para Data Science que estão associadas à modelagem.
Temos o de amostra e de população, por exemplo; a ideia de erro; a ideia de probabilidade, que inclusive faz parte do resultado do classificador naive-bayes; e temos também a noção de correlação, que descreve a relação entre variáveis.
Quanto a esse último, por exemplo: é muito utilizado como uma forma de compreensão de variáveis em bases de dados. Para aprender em um contexto supervisionado, um algoritmo deve, entre outras coisas, estudar a correlação entre os atributos que estão na base de treinamento (entender se um cresce quando o outro cresce ou não).
Além disso, na clássica técnica não supervisionada das regras de associação, especificamente no algoritmo a priori, utilizamos também vários conceitos estatísticos. Estabelecemos níveis de confiança e de suporte (duas noções estatísticas) que definem a certeza de uma regra e a proporção de um certo elemento na base de dados, respectivamente.
Na Ciência de Dados, há também a noção de estatística inferencial, que pode também gerar um modelo. Em definição, a inferência visa levar uma conclusão de uma amostra para uma população, ou seja, generalizar o que foi encontrado em um contexto de amostragem.
No dia a dia da pessoa cientista de dados, pode ser comum utilizar recursos inferenciais para lidar com bases em que existem dados faltantes e desconhecidos. Nesse caso, realizam-se alguns processamentos-padrão para lidar com essas falhas e resolvê-las para que seja possível realizar predições ou outras análises.
Por outro lado, técnicas inferenciais como os testes de hipóteses podem ser usadas para extrair conclusões de um conjunto de dados antes mesmo do processamento por um algoritmo inteligente. Esses testes permitem concluir se uma hipótese é confiável ou não para uma determinada população, a um certo nível de erro provável que é estabelecido.
….
Como vimos, a área de estatística e a de Data Science apresentam uma relação profunda. Uma depende da outra. Criar modelos estatísticos faz parte do trabalho de toda pessoa que trabalha como cientista de dados, por isso, o conhecimento deve fazer parte do seu currículo.
Você não precisa ser um grande especialista, mas deve saber os conceitos fundamentais, como alguns dos que citamos aqui.
Se você já está em sua jornada de aprendizado em Data Science e quer começar a buscar por vagas de cientista de dados, leia nosso guia completo sobre como começar uma carreira na área. Baixe o e-book gratuito e aproveite todas as dicas!



