
Versatilidade é a palavra de ordem para quem quer atuar com Data Science. Tenha uma visão completa sobre a área que une compreensão de dados, visão de negócios e programação.
“Procurada”, “vantajosa”, “quente” e até “sexy” — são vários os adjetivos usados para qualificar a área de Data Science, ou Ciência de Dados. E não é para menos: esse é um campo recente e já está na mira das empresas mais interessantes e poderosas da atualidade. Inclusive, tem gerado resultados incríveis para diversas empresas.
Isso porque Data Science é uma vasta combinação de habilidades: visão holística e estratégica; entendimento dos modelos de negócio; capacidade de identificar e priorizar problemas reais por meio de análises de dados. Ainda é preciso capacidade de aplicar técnicas de estatística, programação e machine learning/deep learning adequadas para solucionar desafios.
Criamos este guia completo para ajudar você a desenvolver sua visão sobre a área de Data Science, a lógica do uso de dados nas empresas e as possibilidades de carreira em Ciência de Dados.
Você vai aprender:
- O que é Data Science
- Como a Ciência de Dados e a Inteligência Artificial se relacionam
- Qual é o ciclo de vida de um projeto em Data Science
- Qual a relação entre Data Science e negócios
- Como trabalhar com Data Science
- Quais são os conceitos da área que você precisa conhecer
Vamos lá? Continue a leitura e se aprofunde no assunto.
O que é Data Science?
Chamamos de Data Science a área que estuda a coleta, o processamento, o tratamento, a análise, a modelagem e a visualização de dados. Geralmente, os dados passam por esses processos para serem convertidos em insights e em informação para gerar conhecimento e viabilizar a tomada de decisões nas empresas.
É uma área que envolve muitos campos interconectados: negócios, matemática, estatística, programação e outros. Está associada a estratégias de construção de arquitetura de armazenamento de dados, criação de modelos e algoritmos para análise e geração de formas de visualizar e comunicar os dados de uma forma mais compreensível.
Os insumos principais para a Data Science são os dados massivos gerados em todo lugar atualmente. A ideia de Big Data é fundamental para entender isso. São dados em diversos formatos e tamanhos, gerados em bases massivas, estruturados ou não estruturados, com erros e/ou ruídos.
Nesses dados, a pessoa responsável, chamada de data scientist, terá que tratar as bases, buscar padrões e tendências e, eventualmente, automatizar a análise, caso precise. Para isso, existe uma série de ferramentas, padrões e linguagens que mencionaremos ao longo deste guia.
Não podemos falar de Data Science sem enfatizar seu foco em negócios. Não se trata somente de analisar os dados. A área envolve uma análise que se volta a problemas reais e a responder questionamentos que estão sendo feitos. Desse modo, a pessoa cientista de dados precisa ter uma boa visão do negócio para saber o que priorizar e o que descartar em suas análises.
A área de Ciência de Dados é extremamente ampla e continua em constante crescimento. Nela, você pode se especializar em engenharia de dados, em visualização, em modelos de machine learning, em testes e otimização de algoritmos, entre outras funções.
Como a Ciência de Dados e a Inteligência Artificial se relacionam?
Você com certeza já ouviu os termos Ciência de Dados e Inteligência Artificial serem usados como sinônimos em muitos contextos, não é mesmo? Contudo, existe uma diferença conceitual muito importante que você vai descobrir a seguir.
Primeiro, a Ciência de Dados é uma área geral que engloba outras áreas e diferentes fases de processamento dos dados. É um conceito-chave para encapsular métodos que visam coletar dados e transformá-los em insights para o negócio. Por isso, há muitas ramificações e termos específicos em cada uma das etapas.
Um desses ramos é justamente a Inteligência Artificial. IA é uma área da Ciência da Computação que estuda formas de desenvolver sistemas artificiais autônomos e, por sua vez, fornece recursos para análises automatizadas em Data Science.
Então, a IA compõe uma parte da Ciência de Dados, como se fosse um conceito dentro do guarda-chuva Data Science. A IA vai lidar com a massa de dados para fins de analisar e tentar aprender sobre esses dados, com identificação de padrões/tendências e modelagem para estabelecer predições.
Na teoria, a inteligência artificial automatiza o trabalho que poderia ser feito por humanos. No entanto, a verdade é que as bases de dados são tão grandes que seria impossível fazer uma análise sem recursos tecnológicos robustos. Podemos dizer que a inteligência artificial não é de fato inteligente no sentido humano, ela é só mais rápida: realiza processamentos persistentes de tentativa-e-erro em segundos.
Com isso, entramos nas concepções de deep learning vs machine learning, tecnologias cada vez mais discutidas. Machine learning (ML, ou aprendizado de máquina) é uma subárea da IA, que coloca em prática a ideia de construir algoritmos para identificação de relações entre dados e padrões.
ML envolve diversos algoritmos e técnicas que ajudam nesse processamento dos dados. Alguns deles são: o algoritmo de naive-bayes, as árvores de decisão, regras de associação, algoritmo k-means, entre outros. Dentre esses métodos, temos as redes neurais artificiais, que envolvem uma simulação do raciocínio humano em termos do funcionamento dos neurônios em camadas.
O Deep Learning corresponde a uma forma de rede neural mais avançada e profunda, com múltiplas camadas de processamento. É um aprendizado mais robusto e especializado.
Para deixar essas ideias mais visuais, trouxemos abaixo uma representação simples dessa relação entre Machine Learning, Deep Learning e Inteligência Artificial, publicada por Jun Wu no blog Towards Data Science.
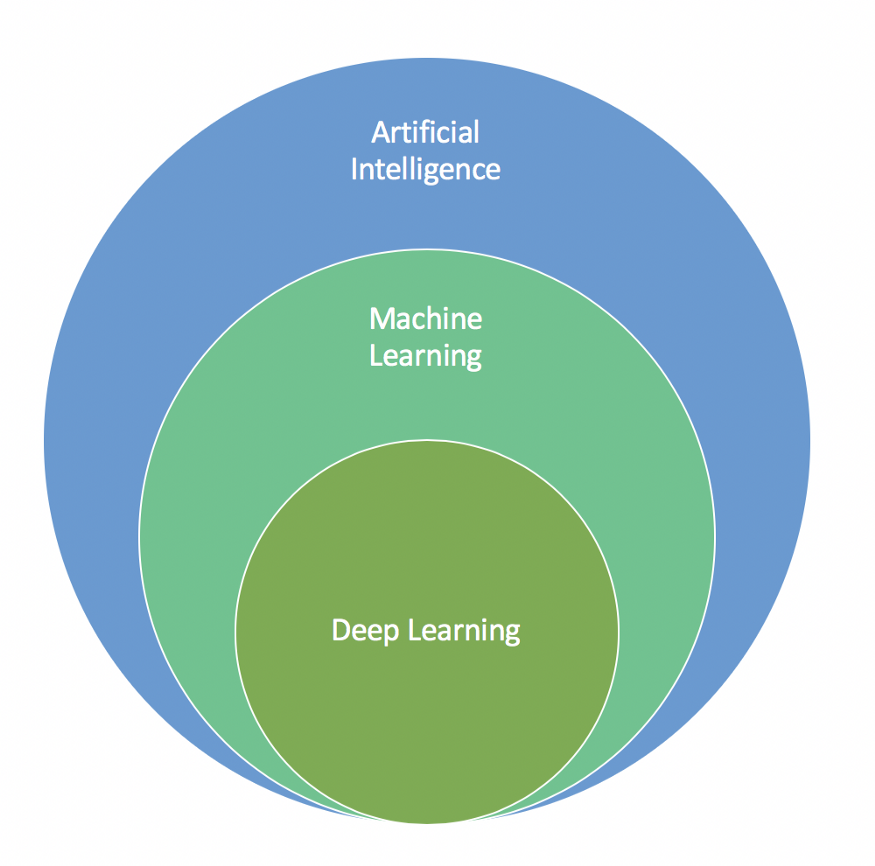
Para concluir, vale lembrar: tanto ML quanto DL são métodos usados para uma parte específica em Data Science e devem ser seguidos dos processos de visualização dos dados, deploy e outros. Em alguns casos, essa modelagem com esses conceitos nem mesmo é necessária, já que tudo depende do objetivo da análise.
Data Science na prática: qual é o ciclo de vida de um projeto?
Como falamos, a área de Data Science visa compreender problemas reais de negócio e encontrar padrões nos dados que ajudem a resolver esses problemas. Por isso, nada melhor para entender o conceito do que analisar como ele funciona na prática. Como estamos falando de uma “ciência”, naturalmente temos um método associado, com fases específicas.
Antes de começar, é importante deixar claro que as etapas citadas aqui são um exemplo de um processo que pode variar, dependendo de quem está realizando as análises, dos seus objetivos, do tipo de negócio e do contexto analítico da empresa.
Existem frameworks prontos com essas etapas, mas, na prática, a pessoa cientista de dados pode escolher seguir o mais adequado para entender e resolver o problema.
Neste tópico, vamos compartilhar um possível ciclo de vida de projeto em uma empresa da área financeira. Vamos usar como exemplo um problema existente em bancos: análises de crédito. Dessa forma, esperamos que você veja com maior clareza como se aplica a Ciência de Dados para realizar essas análises e quais são as atividades rotineiras em cada uma das oito etapas.
1. Identificar o problema
O primeiro passo para começar a aplicar Ciência de Dados é entender qual é exatamente o problema que se busca resolver. No nosso caso, a situação é a necessidade de um sistema que analise os riscos de conceder crédito a um determinado cliente. Afinal, busca-se eliminar riscos de inadimplência e de falhas no fluxo financeiro da instituição bancária.
Nesse momento, é importante realizar vários questionamentos e trabalhar em conjunto com stakeholders que dominam a questão do modelo do negócio. Assim, você conseguirá entender as variáveis importantes e o que é preciso priorizar nesse contexto. Então, vai poder definir objetivos e critérios de sucesso.
2. Coleta e carregamento de dados
Depois de identificar o problema e traçar uma possível solução, é necessário buscar os insumos, a matéria-prima. Em nosso exemplo fictício, vamos considerar que os insumos são uma base de dados histórica do banco, que agrega dados de diversos clientes com características financeiras e os riscos associados aos seus perfis de crédito.
A ideia é adotar essa base e utilizá-la de alguma forma para realizar uma previsão do risco de um cliente novo. Ou seja, a partir de informações referentes aos clientes existentes, tentaremos predizer os riscos a partir da compreensão de como as variáveis estão relacionadas com o risco.
Podemos então criar um código em uma linguagem de programação, como Python, para realizar o devido carregamento dessa base.
3. Tratamento dos dados
Ok, já temos os dados. Nesse momento, uma análise até mesmo visual neles revela algumas questões: eles estão muito desorganizados e carregam falhas significativas. Em Data Science, é comum lidar com dados faltantes, dados errados, dados em uma escala diferente, dados categóricos (que estão em string), dados não importantes para o objetivo, entre outros.
É dever da pessoa que lida com essa função tratar esses dados. Você deve preencher ou ignorar os espaços faltantes, ajustar a escala dos dados para que isso não gere uma tendência errônea na nossa análise, converter todas as strings em números caso, etc.
Muito dessa parte de processamento depende do tipo de algoritmo que será usado para a análise posteriormente, contudo, existem algumas ações-padrão que podem ser seguidas na maioria dos casos.
4. Visualização e exploração
Uma vez que os dados já estão limpos, você pode tentar visualizá-los e explorá-los de modo a obter alguns insights desde já. É o que chamamos de análise exploratória. Assim, é possível construir gráficos para utilizar, inclusive, em reuniões com os gestores e decisores.
Essa primeira análise é limitada, já que é baseada inteiramente na percepção humana, mas já permite alguma compreensão de correlação entre variáveis e padrões.
5. Definição dos algoritmos de análise
Nesta etapa, temos a definição dos algoritmos que poderão ser usados. Nesse momento, utilizam-se os conceitos de Machine Learning e Deep Learning que vimos anteriormente. Para escolher, você deve analisar a complexidade do problema, o número de registros na base e a necessidade por velocidade e precisão.
6. Modelagem
Finalmente, é hora de realizar a análise automatizada com a modelagem. Nesse momento, você vai submeter a base de dados a um algoritmo preditivo (de classificação) para que ele aprenda as relações entre variáveis em sua base de dados histórica. Então, teremos um modelo capaz de predizer se um cliente novo terá um risco de crédito alto ou não.
7. Testes e avaliação
Muitas pessoas consideram a parte do treinamento dos modelos a mais divertida. Já a parte de testes e avaliação tende a não ser tão empolgante. Consiste em avaliar a precisão e a capacidade de acerto do nosso modelo. Em nosso exemplo, com a comparação de uma base de dados de testes e uma base treinada. Saberemos, portanto, qual é a probabilidade do algoritmo classificar corretamente um novo registro.
Caso os testes sejam insatisfatórios, pode ser necessário realizar uma nova iteração do processo com um algoritmo diferente. É interessante utilizar diferentes algoritmos justamente para fins de comparação. Nesse sentido, a pessoa que cuida da análise vai escolher o que gerar melhores resultados.

8. Comunicação dos resultados e produção
Depois de ter encontrado uma opção interessante de algoritmo para análise de risco de crédito, é preciso realizar a última etapa do processo de Data Science: a comunicação para outras pessoas. Ou seja, é preciso transmitir os resultados encontrados de uma forma compreensível para stakeholders, com formas de data visualization e até mesmo storytelling.
Além disso, em alguns casos, é preciso também colocar o modelo treinado em produção, isto é, em um ambiente onde possa ser usado por profissionais para realizar a análise preditiva.
Ao ser adaptado a um sistema com uma interface gráfica, provavelmente desenvolvido por um front-end, o algoritmo poderá ser usado por pessoas que atendem os clientes novos para responder a eles sobre a possibilidade de conceder crédito ou não.
Case: como foi a experiência da Pandora?
Para ilustrar tudo isso, nada melhor do que um case real. Trouxemos para você conhecer o caso de Gordon Rios, primeiro Data Scientist da Pandora, rádio online norte-americana e responsável pelo ambicioso Music Genome Project.
O desafio enfrentado por ele e pelo time que foi montado era complexo: olhando apenas para números comportamentais, eles precisavam determinar se os ouvintes estavam felizes com o que ouviam, se pulavam músicas porque não as conheciam ou se simplesmente não gostavam — além de entender se as playlists estavam entediando as pessoas.
Rios contou em uma entrevista para o portal First Round, que a solução veio do trabalho em conjunto de diferentes áreas. “Você precisa de colaboradores das áreas de operações, engenharia, produto e data scientists, ‘atacando’ o problema de diferentes lados”, conta.
“Claro que algumas vezes você vai ter que ser um verdadeiro soldado e atacar problemas pouco interessantes, mas críticos para o negócio. Mas se tiver talentos incrivelmente ricos no grupo, combiná-los nos projetos certos é a melhor definição de gestão científica.”
A solução, para ele, é uma só: “Você precisa fazer parte do time para entender todas as peças em jogo”.

Como diminuir a distância entre Data Science e negócios?
Não é um desafio incomum: frequentemente empresas tentam adotar Data Science e falham por um abismo entre a área e a visão de negócios. Como lidar?
Como o exemplo de Gordon Rios demonstra, o insight é que os cientistas de dados precisam focar mais na operação.
Selecionamos alguns pontos fundamentais para diminuir o abismo entre Data Science e negócios:
-
Entender para atender: o time de ciência de dados precisa entender, na íntegra, de forma empática, as decisões-chave que os gestores estão tentando tomar. Só então os cientistas poderão apresentar resultados analíticos que vão contribuir para essas decisões.
-
Criar laço com os objetivos-chave: para garantir que os resultados analíticos sejam relevantes para a empresa, é também indispensável estabelecer um laço entre esses resultados e os principais objetivos de negócio: eficiência, custo, receita.
-
Viver e respirar o business: em qualquer empresa, sempre há pessoas experientes em termos de relação com clientes, de desenvolvimento de produto, de mercado etc. Os data scientists devem “colar” nelas. Devem trocar constantemente e de forma ágil para dar transparência à evolução dos projetos e experimentos. E os feedbacks dessas pessoas vai indicar se estão no caminho certo ou não.
-
Medir os resultados: um time de Data Science só deve começar um projeto se souber o porquê de ele existir, e como ele ficará se for bem-sucedido. Não tem segredo: se você não utilizar um placar, só estará treinando, e não jogando.
Concluindo: a Ciência de Dados pode ser uma das atividades mais quentes do momento. Mas, para que realmente faça a diferença dentro de uma empresa, profissionais de dados precisam ir além da tecnologia, entendendo a fundo o negócio a ser amparado pela análise. Focar nos pontos que mencionamos acima é fundamental para quem quer se destacar em uma profissão que, por si só, ganha cada vez mais destaque.
Como diz Rios, “Para ser um cientista de dados de verdade, você tem que entender que seu trabalho não é apenas sobre a pesquisa. Você precisa quantificar e qualificar o que faz de forma que faça sentido para toda a companhia.”
Como trabalhar com Data Science?
A pessoa cientista de dados, em geral, é aquela que sabe mais de programação que um estatístico e mais de estatística que alguém que atua com engenharia de softwares. Ela encontra padrões precisos, aplica modelos matemáticos avançados e machine learning para responder (e levantar outras) questões-chave de negócios. Além disso, ela realiza predições por meio dos dados para guiar decisões futuras.
Leia também: 8 carreiras em dados que estão em destaque no mercado
Como é uma área bastante quente e visada, o salário tende a ser bem interessante. Segundo o Glassdoor, para São Paulo, o valor médio é de R$ 8.219 mensais. Profissionais das mais diferentes áreas podem migrar para Ciência de Dados, sendo importante contar com um curso de Data Science para conquistar uma base confiável.
Se interessou e quer saber como se tornar data scientist? Confira a seguir quais são as habilidades requeridas para quem quer tentar uma vaga de cientista de dados.
Soft skills importantes
Às vezes, habilidades não técnicas são mais importantes que as técnicas. E elas são mais difíceis de adquirir, porque mexem com nosso lado comportamental. Nos obriga a substituir velhos vícios por novos hábitos.
Algumas das soft skills mais importantes para quem quer ser cientista de dados são:
Capacidade analítica
Lidando com dados, uma grande parte do seu dia será ocupada por resolução de problemas. Você precisará se especializar em estruturar esses problemas e aplicar métodos lógicos para endereçá-los. Um olhar analítico o permite escanear dados, realizar correspondências e cruzamentos para apontar o que eles significam e onde podem ser utilizados.
Comunicação
Dados não significam muito se não são contextualizados. Comunicação acaba sendo uma competência subestimada para áreas de tecnologia, mas pode ser crucial para o sucesso de um projeto.
Afinal, a pessoa cientista de dados deve ser a ponte entre a técnica e o negócio, a teoria e a prática.
Você precisará comunicar suas interpretações, conclusões e resultados para diversos stakeholders, e apenas fazendo-o de forma clara eles podem agir sobre suas descobertas.
Hard skills essenciais
É fácil se perder no mar de tópicos da Ciência de Dados. Você pode perguntar a algumas pessoas no mercado o que precisa estudar e sair com uma lista de 100 itens.
A gente não vai fazer isso com você. Para começar, aqui vão quatro:
Programação
A capacidade de programar é o que vai permitir que você absorva e implemente outros conceitos de forma mais rápida. A linguagem sempre vai depender da sua função, mas Python e R são ótimas opções para quem quer migrar para a Ciência de Dados.
Enquanto R tende a ser bastante popular no meio acadêmico, Python costuma ser a preferida dos profissionais por sua versatilidade e estrutura de suporte. A programação Python é mais simples também em termos de sintaxe.
Matemática e estatística
O quão especializada a matemática é vai depender do seu papel, mas qualquer cientista de dados precisa entender de álgebra linear, cálculo e estatística. É essa última que vai facilitar a navegação pelos dados, para que você possa extrair os insumos que precisa e chegar a conclusões com mais precisão. Estatística para Data Science significa uma série de conceitos que precisam estar consolidados na mente dos profissionais.
Análise e visualização de dados
No mundo dos negócios, analistas de dados focam em explorar grandes grupos de dados para transformar números em ações. Só que analisar os dados vence a batalha, mas não a guerra. Para gerar impacto, você também deve saber como organizar informações de forma visual para explicar e vender aos outros suas conclusões.
Algoritmos
Um algoritmo, em poucas palavras, é um fluxo de etapas bem definidas para resolver um problema específico. Eles são utilizados para fazer com que computadores sigam regras e padrões para executar ações.
É essencial, para um cientista de dados, saber como fazer com que máquinas sigam suas ordens e assumam o trabalho sujo que humanos levariam uma vida para realizar.
Leia também: 7 tipos de cientistas de dados e suas possíveis atuações nas empresas
Quais são os conceitos da área de Data Science que você precisa conhecer?
Quer avançar ainda mais no conhecimento de Data Science? Então conheça alguns termos-chave da área que você deve dominar para exercer a carreira.
Data warehouse
Um data warehouse é uma estrutura de armazenamento de dados em um formato organizado e limpo. Podemos considerar como um conjunto de bancos de dados, com recursos mais avançados para possibilitar análises com relatórios e gráficos. Warehouses são muito úteis e poderosos quando precisamos extrair insights de dados para aplicações de negócio e tomadas de decisão.
Aliás, o warehouse está no centro das diferenças entre analistas de dados e cientistas de dados. É uma estrutura com dados prontos para o trabalho de analistas, o que pressupõe que o trabalho de limpar os dados (dos cientistas) já foi feito.
Data lake
O data lake é considerado como um complemento da ideia de warehouse por ser um repositório para dados brutos, que são salvos exatamente como estão quando são gerados de qualquer fonte. Diferentemente dos warehouses, data lakes não envolvem estruturação dos dados para carregamento (ingestão). Assim, é como uma estrutura para dados que serão úteis e outros que nem mesmo serão úteis.
ETL
O ETL é um conceito que define um método de carregamento de dados para data warehouses. A sigla significa “Extract, Transform and Load” (extrair, transformar e carregar). Isto é, ele segue essas etapas antes de inserir um dado no warehouse: primeiro, coleta, depois transforma para uma estrutura esquematizada e, finalmente, carrega o dado para as bases relacionais.
Deploy
O deploy é o momento de colocar uma aplicação em produção, como dizemos no contexto de engenharia de software. No processo de desenvolvimento, é o momento em que levamos o sistema criado para implantar no ambiente onde ele deverá ser utilizado pelos usuários. Ou seja, é o processo de tornar a aplicação pública para cumprir sua finalidade.
Quando falamos em deploy no contexto de Data Science, queremos nos referir ao momento de transformar os modelos de análise em sistemas completos para serem usados no dia a dia. Ou seja, é o processo de converter um modelo em um software que será usado por profissionais não técnicos. Nesse sentido, data scientists precisam entender o que é deploy.
Modelagem de dados
A ideia de modelagem de dados é criar uma representação da realidade que permita manipulação, criação de hipóteses e estudo aprofundado com predições de comportamento das variáveis estudadas. No contexto de Data Science, o conceito está ligado à ideia de modelagem estatística, que consiste no uso de fórmulas e algoritmos para compreender melhor situações do mundo real.
Um exemplo disso é um modelo de regressão linear para tentar predizer qual valor deve ser concedido a um cliente em um banco de modo que o risco de concessão seja o mínimo.
....
A área de Data Science é extremamente rica e cheia de ideias e conceitos. Ela continua em evolução, por isso, aumente sua bagagem e continue se atualizando se você quer conquistar seu espaço nesse mercado.
Se você quer garantir uma preparação robusta para atuar como cientista de dados, te convidamos a conhecer o curso de Data Science e Machine Learning da Tera. Você vai aprender com profissionais que já atuam em times de dados das melhores empresas do Brasil, e se desenvolver com projetos práticos e mentorias.



