
Um guia sobre o que é Machine Learning, como esse conceito se integra ao universo da Ciência de Dados e como aprender e trabalhar na área.
Antes de chegarmos ao que é o Machine Learning conhecido hoje, que tal um pouco de história? Se você nunca ouviu falar de Alan Turing, ouviu falar pelo menos da 2ª Guerra Mundial. O cientista britânico, famoso por construir uma máquina que decifrava o código Enigma (usado na comunicação criptografada entre forças nazistas), foi peça essencial para a vitória dos Aliados em 1945.
Tema do filme “O Jogo da Imitação”, o aparato inventado por ele e seu time acabou servindo de base para vários outros estudos.
A influência de Turing foi além da criptografia e também abrangeu a noção de computadores inteligentes, com o teste que de fato levou o nome de Jogo da Imitação, em que Turing buscava determinar a capacidade de uma máquina pensar como um humano.
Já no final dos anos 50, o também norte-americano Arthur Samuel, prosseguindo nas pesquisas da área, elaborou um sistema que conseguiu ganhar dele próprio em uma partida de damas.
Foi quando o Machine Learning (ML) surgiu como conceito: Samuel havia descoberto uma forma de garantir aos computadores a habilidade de aprender com base em padrões adquiridos, sem que precisassem ser reprogramados a cada tentativa.
Achou interessante? Ainda há muito mais nesse universo do aprendizado de máquina. Neste artigo completo, vamos falar um pouco mais sobre o que é Machine Learning, como é possível aprender e carreiras profissionais que atuam nessa área. Boa leitura!
O que é Machine Learning? Entendendo o conceito
Machine Learning é uma área que visa entender como tornar sistemas e algoritmos inteligentes e autônomos. O termo em português é aprendizado de máquina, pois a área envolve recursos e técnicas para fazer máquinas aprenderem e evoluírem de forma natural e automática a partir de uma base de dados de entrada.
O sistema busca entender os padrões e as correlações internas dos dados para tentar entender como eles funcionam. A partir disso, gera conclusões e predições.
O ML está dentro do guarda-chuva da inteligência artificial, que é um campo mais amplo e mais antigo também, com estudos significativos desde os anos 50. ML é uma subárea recente, que explodiu no mercado com o aumento dos dados e o surgimento da noção de Big Data.
Tipos de Machine Learning
Vamos continuar entendendo melhor esse tema. A seguir, desenvolveremos os tipos principais de machine learning.
Aprendizado de máquina supervisionado
Algoritmos supervisionados aprendem a partir do treinamento com uma base de dados histórica que já contém as saídas predeterminadas para as entradas. Ou seja, passamos para o algoritmo os resultados prévios no treinamento para que ele consiga estabelecer as relações entre as variáveis que possibilitam chegar àquelas saídas. Quando ele conseguir isso, terá aprendido.
Assim, podemos esperar que o sistema consiga prever um novo resultado, com base no que ele aprendeu.
Imagine que você queira prever quando uma transação de cartão de crédito será fraudada, para, assim, evitá-la: para que seu algoritmo seja capaz de antecipar esse acontecimento, ele precisará entender qual é “a cara” desse resultado esperado (as características de uma fraude), para então aprender o padrão que leva até ele.
Então, quando surgir uma nova entrada (uma transação nova), o sistema será capaz de identificar se é uma fraude ou não de acordo com suas características. Aliás, uma grande vantagem do aprendizado com supervisão é a possibilidade de testar o algoritmo, comparando as saídas previstas com as saídas que já se tem.
Uma delimitação importante quando falamos em aprendizagem supervisionada é a divisão em: classificação e regressão. A classificação busca encaixar um novo registro em categorias específicas (“é fraude” ou “não é fraude”, por exemplo). Já a regressão estima um valor específico (previsão do valor de empréstimo que pode ser concedido por um banco, por exemplo).
Aprendizado não supervisionado
Esse tipo de aprendizado nos permite abordar problemas nos quais não se tem ideia exata de qual deve ser o resultado esperado. Não há um exemplo de resposta para ser usado como referência: o modelo deve trabalhar sozinho para descobrir informações que podem não ser visíveis a olho nu, identificando padrões e processos complexos e tirando conclusões.
Com isso, há menos testes ou modelos que possam garantir a precisão dos resultados. Em vez disso, os resultados são criados pela própria máquina. Um exemplo de aplicação: suponhamos que você tenha 10.000 perfis de clientes em um e-commerce e queira reagrupá-los de acordo com diferentes variáveis, como frequência de visitas, quantidade de produtos comprados ou valor médio de compra.
Há, portanto, um conjunto de dados de entrada, mas o conjunto de dados de saída será gerado sem ter respostas pré-definidas como base — e, com essas estruturas identificadas pelo algoritmo, você poderá segmentá-los de acordo com seus objetivos de marketing, por exemplo.
Aprendizado de máquina semi supervisionado
No tipo semi supervisionado, temos as duas estratégias: preparamos uma parte da base de dados para o aprendizado com saídas predeterminadas e outra parte da base para saídas e conclusões do próprio algoritmo, sem supervisão. O objetivo é garantir uma perspectiva ainda mais ampla e completa.
Aprendizado por reforço
Já no aprendizado por reforço, o algoritmo aprende por meio de recompensas oferecidas de acordo com seus acertos. Quando ele acerta, recompensamos; quando ele erra, nós retiramos algo dele. É como um adestramento de animais.
Um exemplo típico é o aprendizado de robôs que desejam caminhar sozinhos. Quando eles acertam obstáculos, podemos punir o algoritmo, de modo a indicar que esse não é o comportamento ideal; quando eles seguem corretamente, sem acertar nada, oferecemos uma recompensa para indicar que esse é o comportamento ideal.
Relevância de ML nos dias atuais
Machine Learning está em tudo atualmente. Estamos o tempo todo sendo interceptados por aplicações de ML que buscam interagir com os humanos, entendê-los e tentar fornecer valor para as necessidades do dia a dia.
Quando abrimos uma conta bancária com aplicativos, temos ML funcionando; quando abrimos um site de streaming de filmes, temos ML; quando acessamos um e-commerce, vemos ML também. As assistentes virtuais que estão em nossos celulares? Ora, você já sabe.
Por essa razão, é extremamente relevante acompanhar e estudar esse assunto hoje. As pessoas que se dedicarem poderão expandir as possibilidades de atuação, já que podem trabalhar com qualquer área: logística, RH, marketing, direito, saúde, etc.
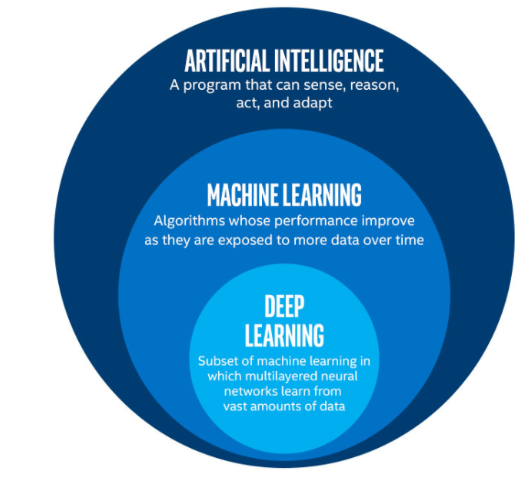
Inteligência artificial, Machine learning e Deep learning: diferenças
Como falamos, o machine learning é um avanço na área de inteligência artificial. Mas o que essa área estudava de fato?
Ora, a inteligência artificial se encarregava de estudar as máquinas e os sistemas artificiais por dentro como se fossem a mente humana. Desse modo, buscava maneiras de fazer os computadores aprenderem como os seres humanos aprendem.
Na prática, isso levou a aplicações bem simples, como toda a subárea dos sistemas especialistas, aplicações de busca e ferramentas que basicamente aplicam regras básicas de lógica matemática (como regras de se-então).
A inteligência artificial é não somente um campo mais geral, como é um nicho bem interdisciplinar. Compreende relações com a filosofia, com a psicologia, com a neurociência e com outras ciências chamadas de ciências cognitivas.
O ML, então, foi um avanço enorme, pois introduziu a ideia de contar com dados como base para o treinamento. A partir desses dados, o sistema deve aprender com os padrões internos deles, aplicando uma série de cálculos estatísticos e matemáticos que permitem processar e entender esses padrões.
Mas, e quanto à relação deep learning vs machine learning? O Deep Learning, por sua vez, é uma subárea do machine learning. Trata-se de uma forma de implementar ML com redes neurais profundas que agilizam o processo de aprendizado e aumentam consideravelmente a precisão. As redes neurais têm esse nome justamente porque tentam simular o aprendizado de neurônios humanos.
Mineração de dados e Machine Learning: diferenças
Há uma confusão muito comum entre o termo mineração de dados e machine learning. Mas não se desespere! Nós vamos esclarecer os dois conceitos.
Chamamos normalmente de mineração de dados as técnicas que visam extrair informação de dados brutos como em um processo de mineração natural mesmo. Assim, compreendem todas as etapas de processamento e transformação até a modelagem para gerar algum valor, com insights e predições.
A área de mineração de dados é muito confundida também com data science, sendo que o primeiro termo é mais comum em alguns espaços acadêmicos.
Já o machine learning, como vimos até aqui, é uma subárea da Inteligência artificial que compreende técnicas específicas para o aprendizado de máquina. Nesse sentido, é um conjunto de algoritmos e mecanismos que permitem identificar padrões e correlações em grandes massas de dados para chegar ao valor final.
Ou seja, o machine learning é utilizado como uma ferramenta para minerar dados. O ML automatiza o processamento dessa grande massa de dados que geralmente se analisa, visto que seria humanamente impossível encontrar os padrões neles.
Então, em suma, o termo mineração é mais geral para o processo de transformar dados em informação útil para tomada de decisão. É focado diretamente nos objetivos principais, que estão associados a suas aplicações em empresas e no mercado em geral, por exemplo.
O aprendizado de máquina é utilizado como uma ferramenta, mas o termo em si corresponde a uma área de estudo de como fazer máquinas aprenderem melhor e mais rápido.
Principais algoritmos de Machine Learning
Nesta seção, faremos um apanhado dos principais algoritmos de machine learning, suas aplicações e diferenças.
Naive-bayes
O naive-bayes é um exemplo clássico de algoritmo supervisionado que intenciona classificar registros em categorias bem delimitadas. Para tanto, ele processa a base de dados e busca as relações entre as variáveis e as saídas em termos de probabilidade e frequência.
Desse modo, gera uma tabela de probabilidade que ajuda a indicar o que é mais provável concluir acerca de um registro novo (em qual classe ele se encaixa). Quando precisa buscar a categoria desse novo elemento, o algoritmo simplesmente busca na tabela o maior grau de probabilidade.

Árvores de decisão
As árvores de decisão também são métodos clássicos para problemas de classificação. Consistem em analisar as características da base de treinamento para estabelecer hierarquias de nós e gerar, portanto, uma árvore como modelo.
Uma árvore de decisão é definida por uma série de regras “se-então”, em uma análise mais geral. Então, quando um novo elemento aparece para ser classificado, o modelo percorre suas regras e chega ao nó final, que é a categoria específica.
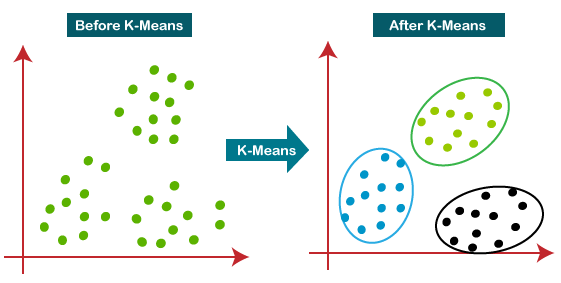
K-means
Esse é um bom exemplo de algoritmo não supervisionado com diversas aplicações interessantes. É um algoritmo de agrupamento, ou clusterização, de dados. Ele permite que definamos um conjunto de clusters em que os dados serão agrupados. A partir desse número, ele realiza alguns cálculos de distância para definir os elementos componentes de cada cluster e separar os dados nesses grupos de análise.
Regras de associação apriori
O algoritmo apriori parte de uma lógica bem simples, muito fundamentada em estatística: busca correlações na base de dados e define as regras de acordo com isso (quando aparece X, aparece também Y). Assim, é possível estabelecer algumas relações entre os elementos e realizar conclusões de acordo com isso. O modelo é, então, um conjunto de regras baseadas em um raciocínio “se-então”.
SVM
O support vector machine (SVM) é um algoritmo poderoso para classificação (reconhecimento de voz e de texto, principalmente). Se destaca por oferecer um desempenho melhor para essas tarefas do que o naive-bayes e as árvores de decisão, por exemplo.
Para isso, ele busca estabelecer um hiperplano de separação entre os dados que apresente uma margem máxima entre registros de diferentes classes. Quanto maior a margem de separação entre os grupos, melhor é a definição da classificação.
Redes neurais
As redes neurais são técnicas de ML que se baseiam no funcionamento do cérebro humano. Funcionam a partir de camadas com diversos neurônios especialistas que processam uma parte da informação. Cada camada transmite um certo resultado às camadas seguintes.
O objetivo do treinamento é definir os pesos ideais para os neurônios. As redes neurais atualmente são o algoritmo favorito do mercado para reconhecimento de voz e de texto, principalmente por conta de ter um melhor desempenho. É até melhor do que o SVM.
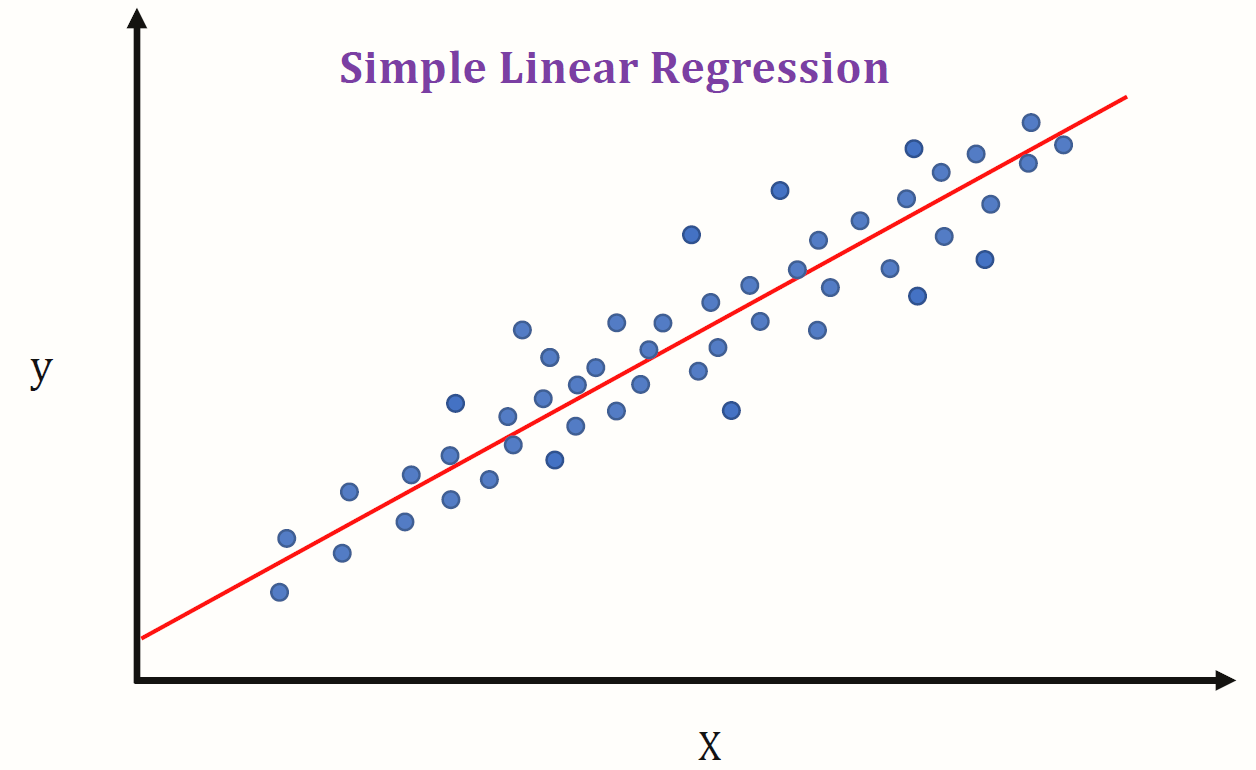
Regressão linear
A regressão linear é um clássico exemplo de aprendizagem supervisionada que realiza uma regressão, em vez de uma classificação. Ou seja, permite predizer números.
Faz isso com uma reta que se adapta melhor aos dados da base de treinamento, sendo que, a partir dessa reta, é possível estimar qualquer valor. A regressão linear é um método clássico de modelagem estatística.
Regressão logística
A regressão logística parte da regressão linear com uma diferença principal: o fato de que busca adaptar os dados a determinados limites numéricos, não contínuos. Afinal, o objetivo dessa técnica é classificar registros em grupos predeterminados, e não estimar um valor numérico (é um método de classificação).
Exemplos do uso de aprendizado de máquina
Neste tópico, vamos conhecer as principais aplicações de ML no mercado atual. Entenderemos como os algoritmos se encaixam nesses propósitos distintos.
Sistemas de recomendação
Os famosos sistemas de recomendação estão muito presentes em nossas vidas. Se você comprar algo, acessar uma loja virtual ou simplesmente ver um filme, será alvo de sugestões inteligentes desses sistemas.
Eles utilizam geralmente uma lógica de correlacionar perfis de usuários, definir grupos com características similares e, então, recomendar a um membro do grupo o que outros gostaram. Isso é um resumo do algoritmo mais comum para esse fim: a filtragem colaborativa.
Para definir os agrupamentos, pode ser utilizada inclusive uma clusterização do tipo K-means. Além disso, recomendações podem ser construídas com o algoritmo apriori também.
Motores de busca
Os motores de busca, também presentes no nosso dia a dia, utilizam recursos de processamento de linguagem natural (NLP) para tratar palavras e termos pesquisados e buscar sua intenção. Eles realizam uma série de processamentos para compreender as palavras, removendo pedaços que não são interessantes na análise (como as chamadas stop words, que são termos gerais, como artigos e conjunções).
A ideia de um motor de busca com NLP é ser muito mais do que um simples sistema que encontra termos em páginas web (o que poderia ser feito com uma função de busca básica). A aplicação intenciona realmente entender o que está sendo dito e apresentar sugestões inteligentes que geram valor.
Segmentação de mercado
No marketing, os algoritmos de clusterização podem ser adotados para realizar segmentação de mercado e personalização de ações e ofertas.
Em uma base de clientes, a empresa pode aplicar essa lógica para dividir perfis e falar com cada um de acordo com suas características. Essa é uma estratégia que foi utilizada inclusive no marketing político que envolveu a campanha de Donald Trump em 2016.
Análise de redes sociais
Outro tipo de agrupamento muito utilizado é o que busca compreender o que está sendo comentado em redes sociais. Ao tratar os dados com o algoritmo, é possível extrair grupos específicos de acordo com o tema que está sendo discutido. É uma ferramenta muito útil para pessoas que pesquisam internet e como as pessoas se expressam nas mídias.
Combate a fraudes em sistemas
A análise preditiva é capaz de identificar indícios de fraudes em sistemas e ajudar a combatê-las de antemão. Isso ocorre devido à detecção de padrões de uma fraude, com um diagnóstico prévio, que é resultado de um treinamento com situações fraudulentas diversas.
Diagnóstico de doenças
Na saúde, tem-se estudado como utilizar ML para diagnosticar doenças com maior precisão. Essa é uma aplicação que parte do campo da visão computacional e utiliza técnicas avançadas de aprendizado de máquina, como o Deep Learning, para processar uma imagem de exame e tentar entender se há ali algum sinal de doença ou não. Isso facilita o trabalho dos médicos e agiliza a detecção.
Filtros de spam
Nos servidores de e-mails que nós utilizamos, roda uma aplicação muito relevante que lê os e-mails e busca identificar se eles são spam ou não. Geralmente, esse algoritmo consiste em um classificador bayesiano, que, portanto, se baseia em probabilidades e em estimativas com base nas relações entre os dados e as variáveis de saída.
Identificação de fake news
Um projeto muito interessante de alunos do curso de Data Science e Machine Learning da Tera visa identificar fake news. O sistema do aplicativo Veritas utiliza processamento de linguagem natural para classificar uma informação em “fake news” ou “não fake news”.
Leia também: De faxineiro a cientista de dados: a história de Moxú
Previsão da inadimplência
Vale destacar outra aplicação muito relevante de estudantes da Tera: um sistema que prevê inadimplência. A partir do treinamento com diversas características de perfil de compradores, ele consegue aprender as relações e prever se uma pessoa nova tenderá a pagar ou não, a partir de um dado grau de probabilidade.
Como trabalhar com Machine Learning
Como vimos até aqui, são muitas as possibilidades no universo do que é machine learning. Você pode trabalhar em múltiplas áreas e migrar de uma área para outra tranquilamente. Agora, vamos explorar um pouco as ocupações mais comuns nesse campo do conhecimento.
Em vagas de emprego, existe a definição geral de cientista de dados. Essa pessoa deve saber processar dados, tratá-los, gerar insights e criar modelos para compartilhar valores com outras pessoas. É uma profissão que envolve forte conhecimento de programação, de estatística e de negócios. Naturalmente, a pessoa terá que lidar com diversas técnicas de ML e precisará saber quais se encaixam melhor em cada problema.
Segundo o Glassdoor, o salário médio para o Brasil inteiro é de R$ 7.620. Já em São Paulo, o salário médio é de R$ 8.357.
Temos também a pessoa engenheira de ML. A principal responsabilidade é a de criar pipelines e fluxos automatizados de treinamento, testes e deploy de modelos. Esse profissional será encarregado de manter a aplicação sempre com um bom nível de precisão e acurácia, mesmo diante de novas features. Nesse sentido, é fundamental conhecer as novas tendências de MLOps.
O salário médio de uma pessoa engenheira de ML é de R$ 9.851 em São Paulo, de acordo com o Glassdoor.
Aliás, há também uma pessoa específica para lidar com essas tecnologias, a pessoa especialista em MLOps. Ela atua junto à pessoa engenheira, pensando em gerar formas eficientes de implantar modelos em sistemas reais. O objetivo é manter o sistema de ML sempre pronto para atender à demanda real de uma empresa ou organização.
Como aprender Machine Learning?
Apesar de ser uma área tão vasta e complexa, aprendizado de máquina não é um bicho de sete cabeças. Existem diversas opções interessantes para quem precisa aprofundar os conhecimentos e dominar a área.
Uma das possibilidades é conferir os livros sobre o assunto. Você pode buscar os clássicos que são referência na área, bem como publicações novas com novos recursos. O nível de didatismo e a explicação com forte embasamento matemático/estatístico são o que destaca os livros.
Para quem gosta de aprender de maneira mais rápida, é possível conferir tutoriais práticos. Você consegue achá-los em sites e fóruns e até mesmo em vídeos na internet. Eles geralmente dão um conhecimento específico sobre algum assunto, sem os temas periféricos que você precisaria para uma compreensão profunda.
Então, se realmente deseja dominar um assunto, o ideal é buscar um bom curso de Data Science e Machine Learning. Nele, você conseguirá ver exemplos sendo feitos, poderá testar em sua própria máquina e aprenderá os melhores macetes sobre como programar nesse campo, com pessoas especializadas que dedicaram suas vidas a estudar esse assunto.
….
Entender o que é machine learning, quais são os algoritmos e as aplicações é essencial como um passo além nesse universo fantástico. É preciso então continuar se atualizando e buscando novas informações para evoluir nessa área e alcançar oportunidades de emprego.
Se você quer continuar aprendendo sobre Ciência de Dados e todas as disciplinas envolvidas nessa área, baixe nosso e-book gratuito "Data Science: o guia completo para começar na área".



