
A engenharia de dados é um processo fundamental para controlar os dados e prepará-los para análise. Conheça a área!
Para tratar dados e criar modelos inteligentes, é necessário lidar com uma etapa preparatória. Essa etapa compreende a coleta de dados e alguns outros processos introdutórios que às vezes podem ser executados pela mesma pessoa que gerencia a criação dos modelos e da visualização. Chamamos essa fase de engenharia de dados.
A engenharia cuida dos dados em um formato inicial, quando ainda estão muito ligados a suas fontes. Dentro do ciclo de desenvolvimento de aplicações de dados, a responsabilidade da pessoa engenheira é enorme e fundamental para que tudo ocorra bem e resulte em predições relevantes e conclusões certeiras.
Quer entender melhor como essa área funciona? Quer também saber como ela se diferencia da ciência de dados e de outras profissões relacionadas? Acompanhe e descubra.
O que é a Engenharia de Dados?
A engenharia de dados é o processo de criação da estrutura de armazenamento dos dados brutos para que eles sejam depois analisados. Cuida da coleta, da preparação e da governança desses dados para garantir que eles estejam em um bom nível de qualidade para a modelagem e para a visualização.
Profissionais da área devem também governar a manutenção dessas estruturas e do pipeline de dados, o que garante que esses dados brutos continuem sendo utilizados no processo de forma eficiente. A engenharia é composta do processo de planejamento da arquitetura e do monitoramento dessa arquitetura.
Em um ciclo comum de dados, a engenharia se encarrega justamente das primeiras etapas, de preparação e cumprimento dos requisitos. Assim, lida com a qualidade e clareza desses dados, bem como com a infraestrutura necessária, como a composição de Data Warehouses e Data Lakes.
Diferentemente de uma pessoa que administra banco de dados, uma pessoa engenheira tem como principal função o gerenciamento desses dados que chegam de diversas fontes e de diversas maneiras. Elas cuidam do chamado Big Data: dados de batch, gerados em tempo real, de sistemas transacionais, dados da internet, dados externos, etc.
Por isso, precisam de um forte conhecimento de tecnologias que permitam processar esses dados. É essencial o domínio de soluções específicas, como:
-
Apache Spark;
-
Hadoop;
-
Scala;
-
MapReduce.
A engenharia de dados compreende também processos de teste de desempenho e de requisitos da infraestrutura associada aos dados. Nesse caso, se assemelha muito à própria engenharia de software, inclusive.
Por isso, aliás, as pessoas que decidirem seguir essa área deverão também ter um sólido conhecimento em processos de engenharia de software, bem como sobre a parte de infraestrutura de projetos de software.
Engenharia de Dados e Ciência de Dados: qual a diferença?
Dentro do assunto Big Data, vários termos são facilmente confundidos, principalmente porque a área ainda é muito recente. A engenharia de dados em muitos casos se torna um sinônimo de Data Science. Contudo, existem diferenças importantes que precisamos considerar.
Uma delas é que a engenharia precede a ciência de dados em um ciclo típico. Enquanto a engenharia cuida de questões relacionadas à infraestrutura, extração e ingestão, a ciência se encarrega do treinamento de modelos de machine learning/deep learning e de soluções de visualização de insights sobre os dados. As pessoas cientistas começam a partir dos resultados das pessoas engenheiras.
Digamos que haja um projeto de análise de dados de streaming, que surgem em tempo real. A engenharia faz a sua parte: coletar esses dados, prepará-los e guardá-los em uma estrutura robusta e confiável para uso posterior. A depender do planejamento, pode-se escolher entre as estruturas e arquiteturas mais interessantes.
A ciência pega esses dados já tratados e os submete a algoritmos de inteligência artificial para buscar insights e padrões que permitam o aprendizado. Então, cria-se um modelo para prever novas informações com base no que foi aprendido. Depois, a pessoa cientista pode ainda criar gráficos e estruturar dashboards para compartilhar o que foi encontrado.
Entretanto, vale destacar: essa divisão exata entre as atribuições depende muito do nível de maturidade e do tamanho da empresa. Em empresas maiores e já maduras, a divisão faz todo sentido, já que a complexidade do trabalho de cada profissional já é enorme o suficiente.
Contudo, em companhias menores, é comum ter uma pessoa responsável por gerenciar os dados, cuidando tanto das funções de engenharia quanto das funções de ciência. Essa pessoa coleta os dados, cuida deles em um estágio inicial e também treina algoritmos com eles para obter previsões.
Nesse sentido, em empresas menores, os dois termos de fato se tornam sinônimos. Vagas para engenharia de dados acabam trazendo também funções de cientistas, ao passo que vagas para ciência de dados trazem funções de engenharia.
Para esses projetos de menor escala, a pessoa que se dedica a tentar a profissão deve conhecer Hadoop, MapReduce, Scala, linguagens de programação, funções e bibliotecas, ferramentas de desenvolvimento e outros.
Há casos específicos em que a pessoa cientista de dados pode ser também responsável pela implantação dos modelos em outras aplicações, criando apps e sistemas que utilizam aqueles modelos.
Em suma, podemos definir a função de engenharia de dados como focada nos dados em si: na qualidade deles, no ciclo de governança e na sua disposição para outras funções. Ao passo que a ciência de dados foca nos modelos e algoritmos, com os dados apenas como um ponto de partida mesmo.
Atuação e responsabilidades da pessoa engenheira de dados
Neste tópico, vamos aprofundar um pouco mais as atribuições das pessoas engenheiras de dados. Falaremos de algumas questões que já surgiram na primeira parte deste artigo, mas com mais detalhes.
Ingestão
A ingestão diz respeito a todo esforço para coletar os dados e permitir que eles entrem nas estruturas de armazenamento da empresa. Nesse caso, inclui o tratamento das diversas situações em que os dados são inseridos: como batch, streaming, dados de sensores, dados de sites, etc.
Cuida da conexão com esses sistemas e das operações ETL (extrair, transformar e carregar) e ELT (extrair, carregar e transformar).
A pessoa responsável constrói um ecossistema que recebe os dados de acordo com a frequência desejada. A princípio, eles podem ser colocados em um data lake, por exemplo, para que depois se tornem informações valiosas para determinados fins.
Esse processo também deve cuidar de possíveis problemas no recebimento de dados, como questões de instabilidade dos sistemas que enviam os dados.
Modelagem
Outra parte importante do dia a dia de quem lida com a engenharia de dados é a modelagem de dados. Em suma, se trata de adaptar os dados a um determinado modelo de organização que facilite as análises que serão realizadas.
Um dos mais usados atualmente é o esquema fato-dimensão, que estabelece algumas informações, como fatos que se quer analisar e algumas características que permitem filtrar esses dados como dimensão.
A modelagem também serve para remover dados duplicados, dados conflitantes e inconsistentes. É a organização desses dados para que se tornem bases para visualização ou para o treinamento de modelos.
Segurança
A segurança também é de extrema importância. As pessoas engenheiras devem cuidar da acessibilidade dos dados, de modo a mantê-los sempre prontos e disponíveis, assim como do controle de integridade — a validez e clareza deles. Da mesma forma, essas pessoas se encarregam de favorecer o cumprimento de normas de proteção de dados e de segurança da informação.
Essa responsabilidade se tornou ainda mais relevante ultimamente, com o aumento das discussões sobre proteção de dados e leis sobre privacidade e segurança.
Não somente é necessário manter os dados robustos e seguros nas plataformas de armazenamento, como é fundamental controlar a qualidade, a disponibilidade e a integridade desses ativos.
Ou seja, os dados devem estar em boas condições para as análises por algoritmos inteligentes. Da mesma forma, eles devem estar sempre disponíveis e protegidos contra possíveis ameaças.
Limpeza
Para efetuar a limpeza, a engenharia de dados envolve cuidados que processam os dados para prepará-los para a utilização em dashboards ou como input para determinados algoritmos de processamento.
É a ação de remover inconsistências, preencher/remover dados vazios e nulos, remover dados inválidos e converter os dados para atender a um formato mais interessante.
Busca de fontes de dados
Também é dever da pessoa na função de engenheira de dados a busca por novas fontes e a integração entre os sistemas para obter dados funcionais e de qualidade.
Arquitetura
A construção da arquitetura é, como já falamos, uma das principais atribuições da engenharia de dados. Consiste em projetar e desenvolver o pipeline, com as regras que oferecem os melhores resultados para a gestão. É bom pensar o termo “pipeline” como um tubo que fornece um caminho para os dados em uma sequência linear.
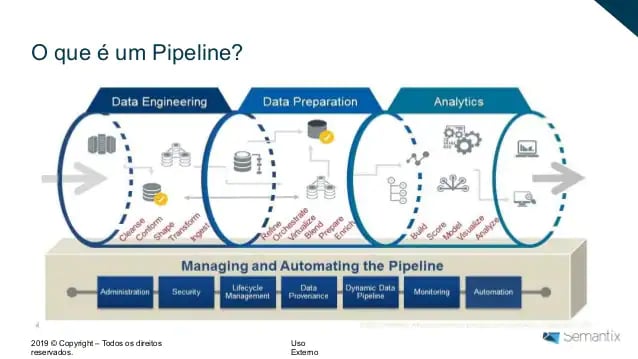
Fonte: Blog Sudoers
A arquitetura envolve definir como os data lakes serão estruturados, como serão suas camadas e como os dados vão fluir de uma parte para outra; se os dados serão analisados em batch (processamento agendado) ou em tempo real; como o warehouse vai receber os dados, entre outras questões.
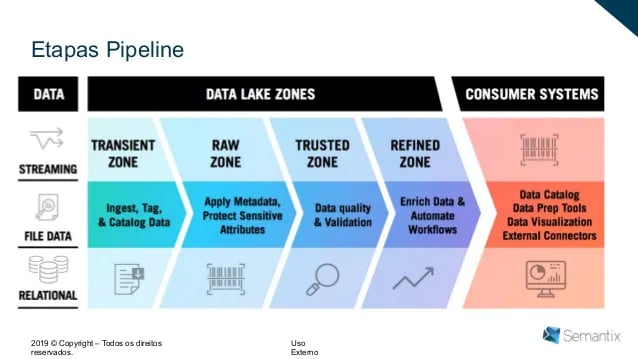
Fonte: Slideshare
Como funciona uma formação para Engenharia de Dados?
Uma formação para engenharia de dados passa por conhecimentos acerca de outras áreas no mundo da tecnologia.
Primeiro, a pessoa precisa dominar o universo da programação e saber as linguagens mais importantes para lidar com dados, como Python. Além disso, é necessário dominar ferramentas de bancos de dados e estruturas de armazenamento mais complexas, bem como esquemas de leitura e de modelagem.
Outro conhecimento útil é o de ferramentas na nuvem, principalmente para atuar hoje. Atualmente, com as demandas crescendo por arquiteturas flexíveis e robustas, as empresas estão cada vez mais buscando soluções na cloud para tratar seus dados. Por isso, além de conhecer como funcionam as ferramentas na teoria, é preciso saber os nomes e dominá-las.
Tecnologias como Spark, Hadoop, Amazon S3, Fluentd e bancos de dados que não atendem ao modelo SQL, como o MongoDB, são fundamentais para o currículo de quem se dedica à engenharia de dados.
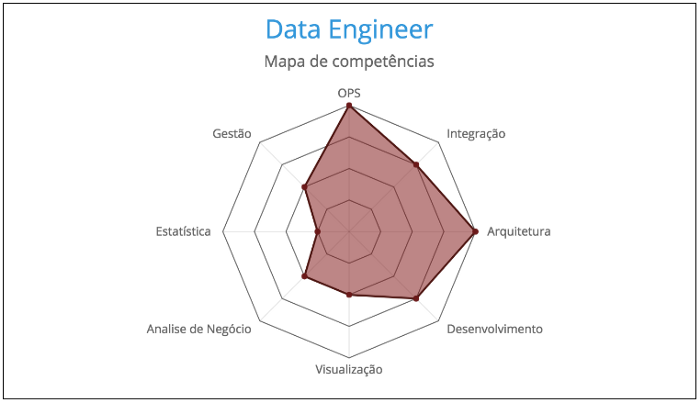
Fonte: Data Hackers
É preciso destacar que uma formação de ciência de dados prepara as pessoas para atuar na engenharia também. Afinal, as carreiras são complementares e partilham muitos dos mesmos elementos, como já discutimos no segundo tópico. Nem sempre os cursos mais simples de Data Science oferecem esse arcabouço, mas um curso completo certamente conta com a estrutura adequada para isso.
Dessa forma, caso a pessoa não encontre um curso específico para engenharia de dados (o que não há, na maioria dos casos), pode confiar em um bom curso de Data Science.
….
A engenharia de dados é uma área completa que gerencia uma questão extremamente importante no ciclo de dados: a entrada deles. Cuida da coleta e prepara os dados para análise, sempre com um olhar voltado para a segurança e qualidade. Como vimos neste post, você pode aprender mais sobre esse campo profissional e conquistar algumas ótimas vagas com um bom curso na área de Data Science.
Gostou do conteúdo deste post? Então, conheça o nosso curso sobre Data Science e Machine Learning.


